学习浏览器渲染原理更多的是为了解决性能的问题
- 执行 JS 有一个
JS 引擎 - 执行渲染也有一个
渲染引擎
渲染引擎在不同的浏览器中也不是都相同的 比如
Firefox中叫做GeckoChrome和Safari中都是基于WebKit开发的
浏览器的渲染引擎
在网络中传输的内容都是 0 和 1 这些字节数据
当浏览器接收到这些字节数据,将字节数据转换为字符串,也就是我们写的代码
HTML
数据转换为字符串以后
浏览器会先将这些字符串通过词法分析转换为标记(token)
这一过程在词法分析中叫做标记化(tokenization)
标记: 属于编译原理的内容
简单来说,标记还是字符串,是构成代码的最小单位
这一过程会将代码分拆成一块块,并给这些内容打上标记,便于理解这些最小单位的代码是什么意思
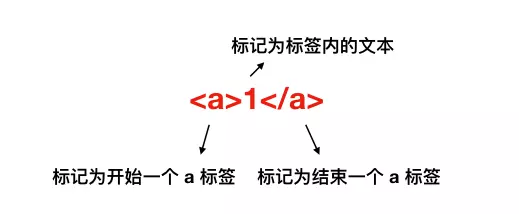
结束标记化后,标记转换为 Node
Node 会根据不同 Node 之前的联系构建为一颗 DOM 树
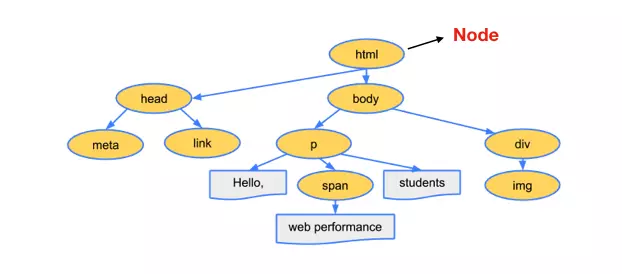

CSS

👆 浏览器得到了HTML的DOM树和CSS的CSSOM树
浏览器需要确定出每一个节点的样式到底是什么,很消耗资源
因为样式你可以自行设置给某个节点,也可以通过继承获得
在这一过程,浏览器递归 CSSOM 树,然后确定具体的元素到底是什么样式
也因为是递归算法,所以减少DOM层级可以减少计算
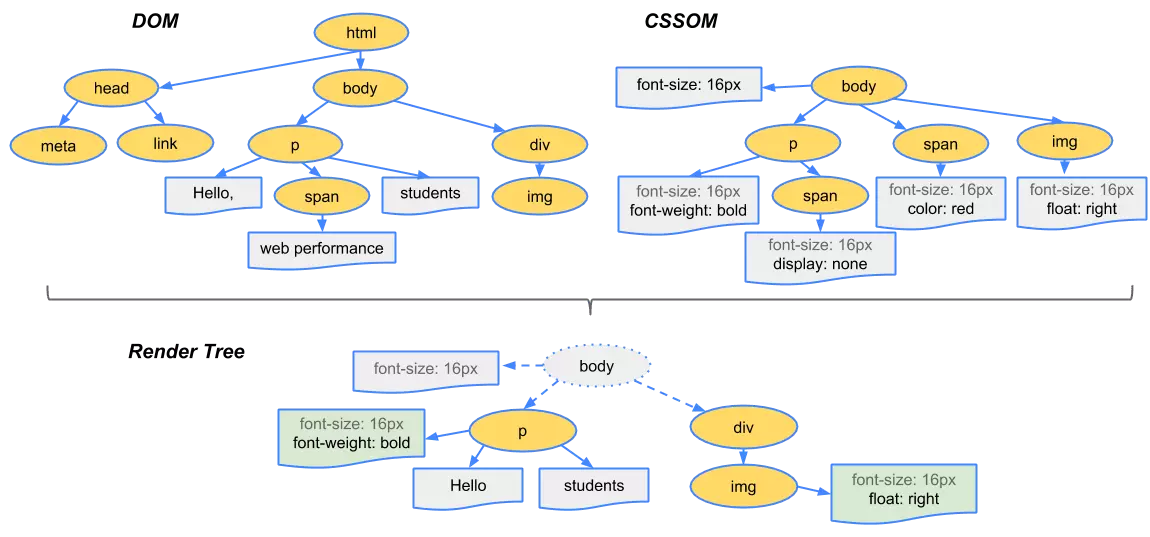
DOM 树和 CSSOM 树,组合为渲染树
不是简单的将两者合并
渲染树只会包括需要显示的节点和这些节点的样式信息
如果某个节点是 display: none 的,那么就不会在渲染树中显示
生成渲染树以后,就会根据渲染树来进行布局(也可以叫做回流)
再调用 GPU 绘制,合成图层,显示在屏幕上
总结
- 浏览器解析
HTML源码标签,根据标签嵌套创建DOM树,并行加载静态资源文件,每一个HTML标签都是文档树中的一个节点,构成了由documentElement节点为根节点的DOM树 - 浏览器解析
CSS代码,计算得出样式数据,构建CSSOM树,非法的语法被直接忽略掉,解析CSS的时候按照顺序来定义优先级:浏览器默认设置 < 用户设置 < 外链样式 < 内联样式 < !important的规则进行解析 DOM树和CSSOM树组成渲染树并绘制渲染树到屏幕上
🤔 什么会阻塞浏览器渲染引擎
- 阻塞生成
DOM树、CSSOM树- HTML、CSS文件网络传输
- HTML的dom层级深
- css选择器优先级复杂
- js立即执行(下载阶段不会)阻塞渲染
- js标签放HTML最下面(最后下载最后执行)
- js标签写
defer属性,放HTML上面,异步下载,但是不会立即执行,而是HTML解析完成后执行 - js标签写
async属性,放HTML上面,异步下载,下载完成立即执行阻塞渲染
🤔 为什么说操作 DOM 慢
DOM 是属于渲染引擎中的东西,而 JS 又是 JS 引擎中的东西。当我们通过 JS 操作 DOM 的时候,其实这个操作涉及到了两个线程之间的通信,那么势必会带来一些性能上的损耗
- 操作 DOM 次数一多,也就等同于一直在进行线程之间的通信
- 操作 DOM 可能还会带来重绘回流的情况,所以也就导致了性能上的问题
面试题:插入几万个 DOM,如何实现页面不卡顿?
不能一次性把几万个 DOM 全部插入
重点应该是如何分批次部分渲染 DOM
- 通过 requestAnimationFrame - 你不知道的js 的方式去循环的插入 DOM
- 虚拟滚动(virtualized scroller) react-virtualized -github
重绘回流
简单概念:浏览器渲染过程有排列(重排/布局/回流)和绘制(重绘)
如果渲染树中的节点被移除、位置改变、元素的显示隐藏等属性改变都会重新执行上面的流程,这一个行为称为回流; 重绘是渲染树上的某一个属性需要更新且仅影响外观、风格,不影响布局,
例如:
- 修改color就属于重绘只是重新绘制到屏幕中上
- 回流必定造成重绘
- 改变 window 大小
- 改变字体
- 添加或删除样式
- 文字改变
- 定位或者浮动
- 盒模型
关于层和GPU这样使用GPU动画
重绘和回流其实也和 Eventloop 有关
- 当 Eventloop 执行完 Microtasks 后,会判断 document 是否需要更新,因为浏览器是 60Hz 的刷新率,每 16.6ms 才会更新一次。
- 然后判断是否有 resize 或者 scroll 事件,有的话会去触发事件,所以 resize 和 scroll 事件也是至少 16ms 才会触发一次,并且自带节流功能。
- 判断是否触发了 media query
- 更新动画并且发送事件
- 判断是否有全屏操作事件
- 执行 requestAnimationFrame 回调
- 执行 IntersectionObserver 回调,该方法用于判断元素是否可见,可以用于懒加载上,但是兼容性不好
- 更新界面
👆 以上就是一帧中可能会做的事情。如果在一帧中有空闲时间,就会去执行 requestIdleCallback 回调
以上内容来自于 HTML 文档
偏移translate替代定位布局的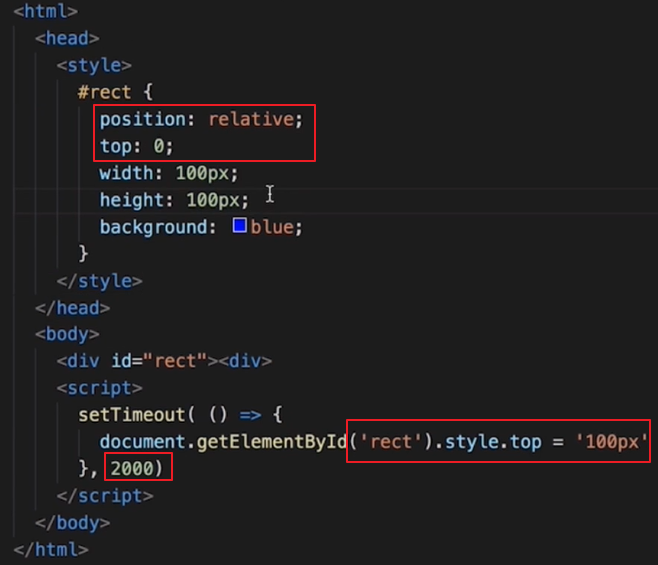
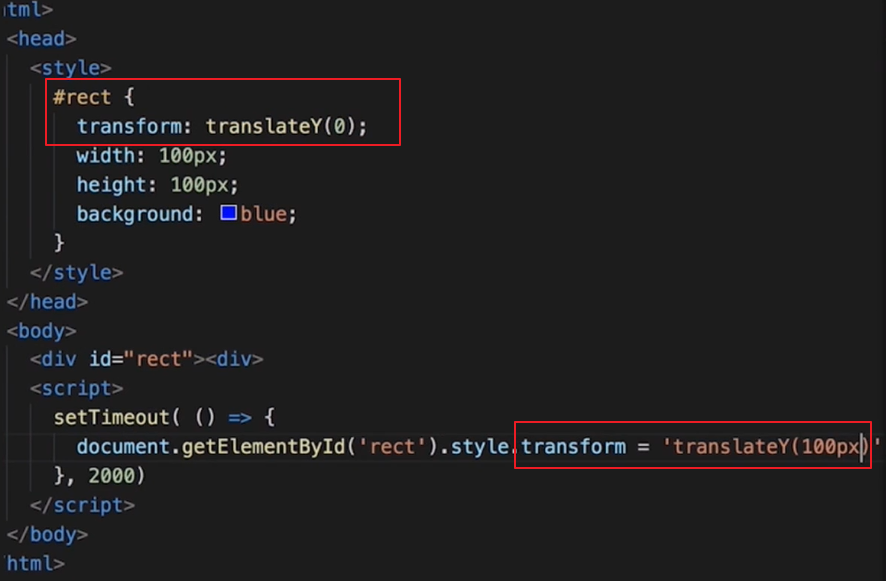 👆 不使用定位布局,而是直接用偏移来修改位置
👆 不使用定位布局,而是直接用偏移来修改位置

 👆 定位布局修改位置绘触发回流(回流一定会触发重绘),偏移修改位置则只会触发重绘
👆 定位布局修改位置绘触发回流(回流一定会触发重绘),偏移修改位置则只会触发重绘
问题:偏移可以完全替代定位布局?偏移会占文档流且无法设置zindex
绝对定位因为本身脱离文档流,再去修改位置其实不会触发其他元素的回流,性能检测上还是能看到有回流,应该是指绝对定位的元素的回流待测
适用于,只想偏移自身,且不想脱离文档流的情况
使用 visibility 替换 display: none ,因为前者只会引起重绘,后者会引发回流(改变了布局)
不把节点的属性值放在一个循环里当成循环里的变量
for(let i = 0; i < 1000; i++) {
// 获取 offsetTop 会导致回流,因为需要去获取正确的值
console.log(document.querySelector('.test').style.offsetTop)
}不使用 table 布局,可能很小的一个小改动会造成整个 table 的重新布局
动画实现的速度的选择,动画速度越快,回流次数越多,也可以选择使用 requestAnimationFrame
CSS 选择符从右往左匹配查找,避免节点层级过多
新建层来优化渲染
将频繁重绘或者回流的节点设置为图层,图层能够阻止该节点的渲染行为影响别的节点 比如对于 video 标签来说,浏览器会自动将该节点变为图层
绘制(重绘)过程: 获取 DOM 并将其分割为多个层(layer) 将每个层独立地绘制进位图(bitmap)中 将层作为纹理(texture)上传至 GPU 复合(composite)多个层来生成最终的屏幕图像。
👆 层的概念是,属于同一层的局部元素进行了重绘,整个层都需要进行重绘?
假设手动设置成了层,其他元素回流重绘,不会影响本层的回流甚至重绘,浏览器重新复合来显示本层内容 但是本图层内的回流重绘并不会有所优化,会影响其他层吗?感觉会
所以独立图层和开启GPU没有减少回流重绘,是利用内存优化加速了渲染
 直接修改margin,触发其他元素一起回流
直接修改margin,触发其他元素一起回流  只修改脱离文档流的元素位置,不影响其他元素
只修改脱离文档流的元素位置,不影响其他元素
通过以下几个常用属性可以生成新图层
- will-change
- video、iframe 标签
🤔 在不考虑缓存和优化网络协议的前提下,考虑可以通过哪些方式来最快的渲染页面,也就是常说的关键渲染路径
提前渲染时机 
加快渲染速度 发生 DOMContentLoaded 事件后,就会生成渲染树,生成渲染树就可以进行渲染了,这一过程更大程度上和硬件有关系了
- 从文件大小考虑
- 从 script 标签使用上来考虑
- 从 CSS、HTML 的代码书写上来考虑
- 从需要下载的内容是否需要在首屏使用上来考虑
JS引擎(V8引擎)
JS 是编译型还是解释型语言其实并不固定
首先 JS 需要有引擎才能运行起来 无论是浏览器还是在 Node 中 这是解释型语言的特性
但是在 V8 引擎下,又引入了 TurboFan 编译器
他会在特定的情况下进行优化 将代码编译成执行效率更高的 Machine Code
当然这个编译器并不是 JS 必须需要的 只是为了提高代码执行性能
所以总的来说 JS 更偏向于解释型语言
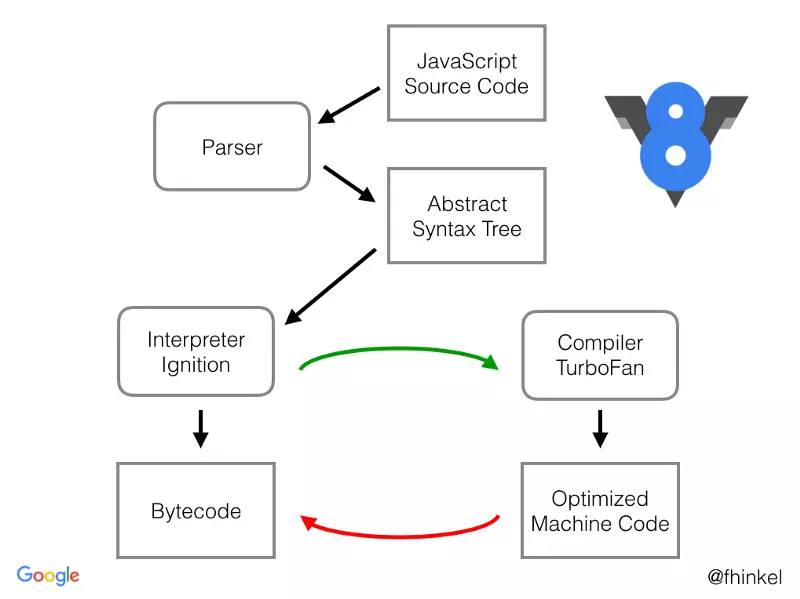
👆 JS 会首先被解析为 AST,解析的过程其实是略慢的。代码越多,解析的过程也就耗费越长,这也是我们需要压缩代码的原因之一。
- JS 代码字符被解析为抽象语法树(AST)
- 通过解释器或者编译器转化为 Bytecode 或者 Machine Code
对于函数来说,应该尽可能避免声明嵌套函数(类也是函数),因为这样会造成函数的重复解析。
function test1() {
// 会被重复解析
function test2() {}
}👆 但是这是 函数式编程高阶函数 避免不了的呀。。。
减少编译时间,可以采用减少代码文件的大小或者减少书写嵌套函数(类)的方式
👇 然后 Ignition 负责将 AST 转化为 Bytecode
TurboFan 负责编译出优化后的 Machine Code,并且 Machine Code 在执行效率上优于 Bytecode

🤔 什么情况下代码会编译为 Machine Code?
👆 提到
TurboFan编译器 会在特定的情况下进行优化: 将代码编译成执行效率更高的Machine Code
JS 是一门动态类型的语言,并且还有一大堆的规则
简单的加法运算代码,内部就需要考虑好几种规则,比如数字相加、字符串相加、对象和字符串相加等等
这样的情况也就势必导致了内部要增加很多判断逻辑,降低运行效率
function test(x) {
return x + x
}
test(1)
test(2)
test(3)
test(4)👆 一个函数被多次调用并且参数一直传入 number 类型,那么 V8 就会认为该段代码可以编译为 Machine Code,因为你固定了类型,不需要再执行很多判断逻辑了
一旦我们传入的参数类型改变,那么 Machine Code 就会被 DeOptimized 为 Bytecode,这样就有性能上的一个损耗了。
所以如果我们希望代码能更多多的编译为 Machine Code 并且 DeOptimized 的次数减少,就应该尽可能保证传入的类型一致。
为了让 V8 优化代码,我们应该尽可能保证传入参数的类型一致。这也给我们带来了一个思考,这是不是也是使用 TypeScript 能够带来的好处之一
const { performance, PerformanceObserver } = require('perf_hooks')
function test(x) {
return x + x
}
// node 10 中才有 PerformanceObserver
// 在这之前的 node 版本可以直接使用 performance 中的 API
const obs = new PerformanceObserver((list, observer) => {
console.log(list.getEntries())
observer.disconnect()
})
obs.observe({ entryTypes: ['measure'], buffered: true })
performance.mark('start')
let number = 10000000
// 不优化代码
%NeverOptimizeFunction(test)
while (number--) {
test(1)
}
performance.mark('end')
performance.measure('test', 'start', 'end')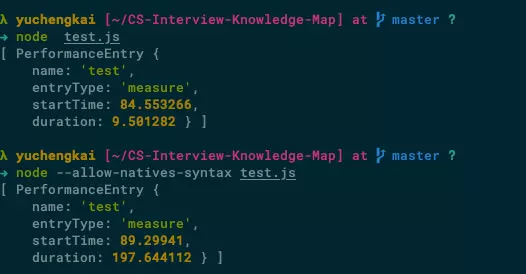
👆 优化过的代码执行时间只需要 9ms,但是不优化过的代码执行时间却是前者的二十倍,已经接近 200ms 了
另外,编译器还有个骚操作 Lazy-Compile,当函数没有被执行的时候,会对函数进行一次预解析,直到代码被执行以后才会被解析编译。对于上述代码来说,test 函数需要被预解析一次,然后在调用的时候再被解析编译。但是对于这种函数马上就被调用的情况来说,预解析这个过程其实是多余的,那么有什么办法能够让代码不被预解析呢?
其实很简单,我们只需要给函数套上括号就可以了
(function test(obj) {
return x + x
})但是不可能我们为了性能优化,给所有的函数都去套上括号,并且也不是所有函数都需要这样做
我们可以通过 optimize-js 实现这个功能,这个库会分析一些函数的使用情况,然后给需要的函数添加括号,当然这个库很久没人维护了,如果需要使用的话,还是需要测试过相关内容的。