跟着视频手写 数组方法 用ts
闭包 = 高阶函数
闭包的概念聚焦在内管回收上
高阶函数的概念聚焦在函数可以用在任何地方(函数是一等公民)
通过把一个函数(回调函数)传递给另一个函数,让另一个函数更灵活
一些常用的js内置数组操作方法,就是典型的高阶函数(回调函数作为参数) 用ts实现
map
// map
// 1.设置一个泛型T
// 传入数组的参数类型 设置为 泛型数组 Array[T],
// 2.设置一个泛型U
// 回调函数中的返回值类型 需要 保持跟我们当前函数返回出去的新数组类型一致
function map<T,U>(list: T[], fn: (item: T, index: number, list: readonly T[])=> U): U[] {
const resultList = []
for(let i = 0; i <= list.length ; i++){
resultList.push(fn(list[i], i, list))
}
return resultList
}测试ts编译效果
// 引入map方法
map([1, 2, 3], (item, index, arr) => {
arr[1] = 2; // 修改readonly参数 编译期间需要报错
console.log(item.length); // 读取item不存在的属性,编译期间需要报错
return item + "2" //
})泛型的使用,需要在函数名后括号前,就提前定义好泛型名
泛型数组的定义方式可以是Array<T> T[]
定义好之后,引用方写回调函数时,item等参数会根据list自动推导出来 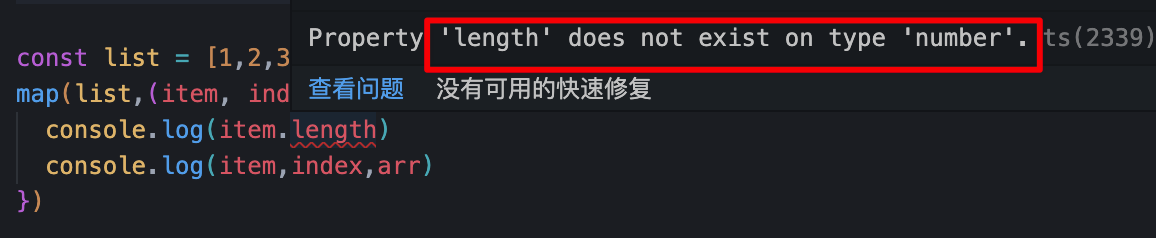
可以给任意类型前加一个 readonly 如回调函数的第三个参数list不允许回调函数修改 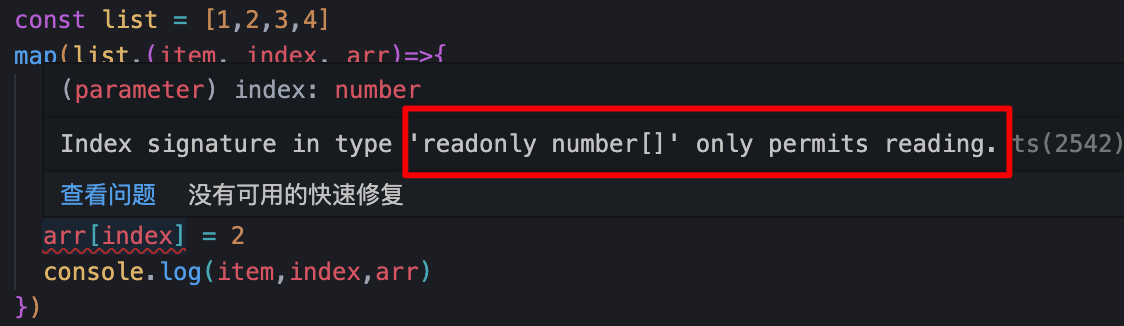
some
/**
* some() 方法测试数组中是不是至少有 1 个元素通过了被提供的函数测试。它返回的是一个 Boolean 类型的值。
* @param list
* @param callback
* @returns
*/
export function some<T>(list: T[], callback: (item:T, index: number, list: T[])=>boolean): boolean {
let result = false
for(let i = 0; i < list.length ; i++){
result = callback(list[i], i, list)
if(result) {
break
}
}
return result
}every
/**
* every() 方法测试一个数组内的所有元素是否都能通过某个指定函数的测试。它返回一个布尔值。
* @param list
* @param callback
* @returns
*/
export function every<T>(list: T[], callback: (item:T, index: number, list: T[])=>boolean): boolean {
let result = true
for(let i = 0; i < list.length ; i++){
result = callback(list[i], i, list)
if(!result) {
break
}
}
return result
}闭包
函数返回函数(高阶函数),并且子函数调用到父级作用域的变量,形成闭包
此时的变量不会被回收
/**
* 只触发一次目标函数
* 函数返回函数,子函数调用父级作用域变量,形成闭包,不会回收done变量
* @param fn
* @returns
*/
export function once(fn:Function):Function {
let done = false
return () =>{
if(done) return
done = true
fn(...arguments)
}
}
function pay() {
console.log('支付')
}
const payOnce = once(pay)
payOnce()
payOnce() // 只会输出一次'支付'闭包的本质: 函数在执行栈上执行,当执行完毕会移除该函数。而变量存放在堆上,变量被子函数引用,而不会被移除(回收)
实操场景下,闭包常用于缓存数据(私有变量)
即可以替代class类的作用了
闭包函数一般用 makeXX 命名
纯函数 Pure Function
相同输入始终会得到相同的输出,并且没有副作用
即纯函数内部处理逻辑没有变量,都是常量
且不会改变目标数据
- 纯函数: Array.slice
- 不纯函数: Array.splice
let arr = [1,2,3,4,5]
arr.slice(0,3) // [1,2,3]
arr.slice(0,3) // [1,2,3]
arr.slice(0,3) // [1,2,3]
arr.splice(0,3) // [1,2,3]
arr.splice(0,3) // [4,5]
arr.splice(0,3) // []lodash中的纯函数
记忆函数
/**
* 以目标函数参数为key进行缓存
* 仅适用于目标函数内容不会变化的东西,如接口返回的数据需要实时更新不能缓存
* 当然短期内不会变化的接口也可以缓存,因为缓存到作用域而已,关闭网页缓存内容就没了
* TODO: 异步记忆函数如何处理
*/
function memoize(fn) {
const cache = {}
return ()=>{
const key = JSON.stringify(arguments)
cache[key] = cache[key] || fn(...arguments)
return cache[key]
}
}
function getSomething() {
console.log('执行一段复杂耗时的处理逻辑')
return 'something'
}
const getSomethingWithMemory = memoize(getSomething)
getSomethingWithMemory()
getSomethingWithMemory()
getSomethingWithMemory() // 只打印了一次‘执行一段复杂耗时的处理逻辑’副作用
上面说到 纯函数内部处理逻辑没有变量,都是常量
这里的变量就是纯函数概念里的副作用
副作用会使纯函数成立不了
而变量常常不可避免,我们应该利用函数包裹尽量避免掉副作用
柯里化 就可以解决副作用变量的问题
把一个不纯的函数,拆分成2个纯函数
柯里化案例 拆分不纯函数案例
自己写一下不使用柯里化的对比
不拆分的话,函数无法复用
函数柯里化
一个函数多次调用传入不同的参数,统一所有参数计算出结果
本质上原理就是缓存住函数的参数
- 利用函数返回函数,来拼接暂存住参数集合
- 加上参数数量的判断条件决定是执行目标函数,还是继续返回包装的未执行函数
// 柯里化函数
const curry = (fn) => {
return function curriedFn (...args) {
// 未达到触发条件(目标函数所需要的参数数量),继续收集参数,不执行目标函数
if (fn.length > args.length) {
return function () {
// slice方法内部的this就会被替换成arguments,并循环遍历arguments,复制到新数组返回,这样就得到了一个复制arguments类数组的数组对象。
return curriedFn(args.concat([].slice.call(arguments)))
}
}
return fn(args)
}
}
const multiply = (x, y, z) => x*y*z;
const curryMul = curry(multiply);
const result = curryMul(1)(2)(3); // 1*2*3 = 6👆是柯里化函数表面上的作用
实操场景下的函数柯里化,可以为我们减少重复代码
// 通过正则匹配字符串中的特定字符,接参数(正则,目标字符)
function strMatchByReg(reg,str) {
return str.match(reg)
}
const str1 = 'qwer111'
const str2 = 'qwer222'
const str3 = 'qwer333'
// 匹配出3个字符串中的空白字符
strMatchByReg(/\s+/g, str1)
strMatchByReg(/\s+/g, str2)
strMatchByReg(/\s+/g, str3)👆 strMatchByReg 相同参数得到相同的结果,所以是纯函数?
这里会发现相同的正则参数需要重复编写
因此考虑复用
- 常量
const SPACE_REG = /\s+/g
// 匹配出3个字符串中的空白字符
strMatchByReg(SPACE_REG, str1)
strMatchByReg(SPACE_REG, str2)
strMatchByReg(SPACE_REG, str3)再把这个函数也复用
- 包装一下这个传入固定正则的函数
function strMatchSpace(str) {
return strMatchByReg(/\s+/g, str)
}
// 匹配出3个字符串中的空白字符
strMatchSpace(str1)
strMatchSpace(str2)
strMatchSpace(str3)上面2种方式,只论复用程度,是第2种创建一个新函数的形式更好
但是这种制造新函数的形式是简单的,还会有其他各种正则制造新函数
而制造新函数的逻辑也可以抽成一个纯函数,那就是柯里化函数
- 柯里化制造新函数
// 通过正则匹配字符串中的特定字符,接参数(正则,目标字符)
function strMatchByReg(reg, str) {
return str.match(reg)
}
const mackStrMatchSomething = curry(strMatchByReg);
const strMatchSpace = mackStrMatchSomething(/\s+/g)
// 匹配出3个字符串中的空白字符
strMatchSpace(str1)
strMatchSpace(str2)
strMatchSpace(str3)经过上面这么多的包装,只是实现一个简单功能,很多时候反而是复杂化了js的逻辑(如果把包装过程的函数放到另外的文件夹,而不是放到一起的话,看起来就会顺眼很多,如果都放一起,看起来就像为了封装而封装)
但是这些代码会非常原子化可复用
另外小经验是,用于逻辑处理的参数放函数前面,目标操作对象放参数后面
(🤔 是不是以后多参数的函数,都柯里化成一个参数来使用,用对象传参反而不太好了)
函数组合
一系列逻辑函数,在平时的操作是,自己写一个处理函数,来调用多个函数 👇
const fn1 = ()=>{}
const fn2 = ()=>{}
const fn3 = ()=>{}
const fn = (params) {
const res1 = fn1(params)
const res2 = fn2(res1)
const res3 = fn3(res2)
return res3
}
fn(params)这个处理函数同样可以作为复用函数使用
用函数组合,则是抽离处理多个函数的逻辑为一个纯函数,不需要自己写处理函数
把多个函数,拼接成一个函数,调用时传入参数,会经过多个函数
const fn1 = ()=>{}
const fn2 = ()=>{}
const fn3 = ()=>{}
const fn = compose(fn1,fn2,fn3)
fn(params)👆 函数组合,其实编写的代码上区别不大。。。但是确实省了很多自己写处理函数的繁琐
实现组合工具方法compose
实际上,当我们真正的按照函数式编程的思维,写着一个一个的原子函数,想要调用的时候往往会出现这样的写法
function fn() {
return 'fn1'
}
function deal(info) {
return info
}
// 把info数据处理一次后,传给fn
const res = fn(deal(info))👆 当我们想要优化这行有点不好看的函数调用时
// 组合任意2个函数
function compose(fn1, fn2) {
return function (val) {
return fn1(fn2(val))
}
}
/****************/
function fn() {
return 'fn1'
}
function deal(info) {
return info
}
const composeFn = compose(fn, deal)
composeFn(info)这样常见的先调处理函数再调其他函数的写法,就能通用的优化成compose了
当然我们还要考虑更多的函数要组合的情况,因此不能简单粗暴的封装成 fn1(fn2(val))
// 组合多个函数 compose
function compose(...fns){
return (value) => {
// 倒序执行
return fns.reverse().reduce((lastRes, fn) => fn(lastRes), value);
}
}
const composefn = compose(fn1, fn2);
composefn('I am value');函数组合示例
有趣的是js原生提供的很多函数,并不能直接的用来做函数组合,如各种数组、字符串函数: 反转数组reverse、字符串大写toUpperCase
因为函数组合的目标函数,需要接收参数,而原生函数是原型链直接取参数
如下反转数组后取第一项大写字符串
function firstItem(arr) {
return arr[0]
}
// 并不能按预期的直接组合起来用
const composeFn = compose(String.prototype.toUpperCase, firstItem, Array.prototype.reverse)
composeFn(['a', 'b', 'c'])👇 而需要对原生函数手动封装一次调用形式(内部还是使用原生函数)
function toUpperCase(str){
return str.toUpperCase()
}
function firstItem(arr) {
return arr[0]
}
function reverse(arr){
return arr.reverse()
}
const composeFn = compose(toUpperCase, firstItem, reverse)
composeFn(['a', 'b', 'c']) // ==> 'C'而这也正是 lodash 内部提供和原生函数重复的各种函数的原因
管道语法
const fn = compose(fn1,fn2,fn3)👆 这种语法同样被人觉得不直观不美观,而函数组合概念里的将结果一路传递到最后的示意图往往是管道
因此会有通过编译原理把函数组合的语法,美化成管道语法的做法,如vue2的过滤器语法
{{ info | fn1 | fn2 }}关于管道函数我们在vue的过滤器中讲到过
注意: ⚠️ 确实把函数原子化,组合起来很方便,但是相对于自己写处理函数时可以写每个步骤的注释,组合函数没办法给每个步骤写注释
所以要给原子函数以及组合后的函数命名好
柯里化+函数组合示例
函数组合的目标函数只能接收一个参数,而我们常常需要组合的函数有多个函数
比如 把never say die 转化为 NEVER-SAY-DIE 步骤
- 大写字符串
- 以空格分割字符串成数组
- 以
-拼接数组
(2、3步可以直接替换空格为-,这里为了使用函数组合,而故意多做一步)
function toUpperCase(str){
return str.toUpperCase()
}
const split(str) {
return str.split(' ')
}
const join(arr) {
return arr.join('-')
}
const spaceToLineAndToUpperCase = compose(join, split, toUpperCase)
spaceToLineAndToUpperCase('never say die') // ==> 'NEVER-SAY-DIE'👆 我们会发现,分割字符串的函数除了要接收目标值,还要接受分割符,拼接数组同理
而我们并不希望 split join 这样本可以复用的原子函数,被写死参数
那么我们的原子函数就要是👇
const split(str, sep) {
return str.split(sep)
}
const join(arr, sep) {
return arr.join(sep)
}这时候我们可以反映过来用一个高阶函数一次接收一个参数,如先接收分割符,形成新函数,这个新函数用于组合时只关注目标数据即可
而这也正是柯里化函数的概念,把需要一次性传递参数 fn(1, 2) 变为 fn(1)(2)
// 注意: 为了最终组合的函数接收的参数是目标数据,要把柯里化函数的参数顺序放对,最后接收目标数据
const split(sep, str) {
return str.split(sep)
}
const join(sep, arr) {
return arr.join(sep)
}
const mackSplit = curry(split)
const mackJoin = curry(join)👇 函数组合
function toUpperCase(str){
return str.toUpperCase()
}
const split(sep, str) {
return str.split(sep)
}
const join(sep, arr) {
return arr.join(sep)
}
const mackSplit = curry(split)
const mackJoin = curry(join)
const splitSpace = mackSplit(' ')
const joinLine = mackJoin('-')
const spaceToLineAndToUpperCase = compose(joinLine, splitSpace, toUpperCase)
// or
// const spaceToLineAndToUpperCase = compose(mackJoin('-'), mackSplit(' '), toUpperCase)
spaceToLineAndToUpperCase('never say die') // ==> 'NEVER-SAY-DIE'函子
- 函数式编程进阶:应用函子
- 深入理解函数式编程(上)
- 深入理解函数式编程(下)
- 日常javascript的函数式编程:组合技术
- Typescript版图解Functor , Applicative 和 Monad
- - [译]函数式JavaScript之Functors
- 什么是 Monad (Functional Programming)?
- 拉勾教育-高阶函数函子部分笔记
- 从纯函数讲起,一窥最深刻的函子 Monad
- 《The Joy of Javascript》阅读笔记2 - Functor/Monad
很多文章教程,上来就介绍函子的概念和原理等,对使用场景和优点没有详细介绍
始终感觉函子的作用和使用场景和柯里化函数组合重复了,只是写法上的不同?因此这里先学习概念和原理,并记录下思考,待以后理解了函子的使用场景后补充笔记
函子与函数组合的写法对比
函子
/** 可优化为箭头函数
function Functor(val) {
return {
// 用then会和原生promise冲突
next: function next(fn){
const res = fn(val)
return Functor(res)
},
resolve: function resolve() {
return val
}
}
}
*/
const Functor = (val)=>({
// 用then会和原生promise冲突 TODO: 《你不知道的js中》
next: fn => {
// 链式处理一次数据存储结果给下一个函子使用
const res = fn(val)
return Functor(res)
},
resolve: () => {
return val
}
})
function toUpperCase(str){
return str.toUpperCase()
}
function firstItem(arr) {
return arr[0]
}
function reverse(arr){
return arr.reverse()
}
function composeFn(val) {
return Functor(val)
.next(reverse)
.next(firstItem)
.next(toUpperCase)
.resolve()
}
composeFn(['a', 'b', 'c']) // ==> 'C'对比一下函数组合
const toUpperCase = str => str.toUpperCase()
const firstItem = arr => arr[0]
const reverse = arr => arr.reverse()
const composeFn = compose(toUpperCase, firstItem, reverse)
composeFn(['a', 'b', 'c']) // ==> 'C'👇 函子的写法其实只是为了让函数组合更好看,更好理解一个组合的步骤吧
// 函子形式组合函数
const composeFn = val => (
Functor(val)
.next(reverse)
.next(firstItem)
.next(toUpperCase)
.resolve()
)
// 函数组合形式
const composeFn = compose(
toUpperCase,
firstItem,
reverse
)看上去这就是函子碾压函数组合的地方。 并不! 实际上如promise支持链式调用,也不是特别好看,毕竟要传入的是一个回调函数,当原子回调函数复杂时,链起来依然丑,也正因为这样才会有async await把链式拍扁
功能性函子
普通函子就是上面的支持链式组合(链式调用+参数传递)的函数
从这个盒子的结构上看,我们是可以拓展很多我们需要的逻辑的
惰性执行函子
函子通过延迟执行、收集异常处理来实现消除副作用的优点,函数组合也都能做到的吧
如下调用普通函子时的执行
// 函子形式组合函数
const composeFn = val => (
Functor(val)
.next(reverse) // 执行回调reverse得到结果并存储
.next(firstItem) // 执行回调firstItem得到结果并存储
.next(toUpperCase) // 执行回调toUpperCase得到结果并存储
.resolve() // 执行
)我们希望调用 composeFn 时先不执行,而是返回一个函子
👇 惰性函子
// 组合多个函数 compose
function compose(...fns){
return (value) => {
// 倒序执行
return fns.reverse().reduce((lastRes, fn) => fn(lastRes), value);
}
}
// 惰性函子,调用next链式时只是组合函数不会真正调用
const LazyFunctor = val => ({
next: (fn) => LazyFunctor(compose(fn, val)),
run: val
})
const mackLazyFn = val => (
LazyFunctor( () => val ) // 创建函子时的参数要包成函数
.next(reverse)
.next(firstItem)
.next(toUpperCase)
)
const lazyFn = mackLazyFn(['a', 'b', 'c']) // 这里传递了参数并不会立即执行
lazyFn.run() // 调用这个才会执行,符合无参数风格编程👇 惰性高阶函数
/**
* 函数式实现惰性执行的工具函数, 传入一个目标函数,返回一个调用也不会立即执行的函数
* const lazyFn = mackLazyFn(callBack)
* const runFn = lazyFn(params)
* const res = runFn()
* 本质就是一个高阶函数(用函数包多了一层)
*/
function mackLazyFn(fn) {
return (...arguments) => {
return () => {
return fn(...arguments)
}
}
}
const composeFn = val => (
Functor(val)
.next(reverse)
.next(firstItem)
.next(toUpperCase)
.resolve()
)
const lazyFn = mackLazyFn(composeFn)
const runFn = lazyFn(['a', 'b', 'c']) // 这里传递了参数并不会立即执行
runFn() // 调用这个才会执行,符合无参数风格编程👇 函子与自实现的lazy函数对比
const lazyFn = mackLazyFn(composeFn)
const runFn = lazyFn(['a', 'b', 'c']) // 这里传递了参数并不会立即执行
runFn() // 调用这个才会执行,符合无参数风格编程const lazyFn = mackLazyFn(['a', 'b', 'c']) // 这里传递了参数并不会立即执行
lazyFn.run() // 调用这个才会执行,符合无参数风格编程参数异常函子
null maybe
条件函子
有一种说法是条件和循环语句都会带来副作用?都不优雅?都不好复用? 因此把条件语句封到盒子里,不让人看到。。。
trycatch
- 违反了[引用透明](原则,因为抛出异常会导致函数调用出现另一个出口,所以不能确保单一的可预测的返回值。
- 会引起[副作用](,因为异常会在函数调用之外对堆栈引发不可预料的影响。
- 违反[局域性的原则](,因为用于恢复异常的代码和原始的函数调用渐行渐远,当发生错误的时候,函数会离开局部栈和环境。
- 不能只关心函数的返回值,调用者需要负责声明 catch 块中的异常匹配类型来管理特定的异常;难以与其他函数组合或链接,总不能让管道中的下一个函数处理上一个函数抛出的错误吧。
- 当有多个异常条件的时候会出现[嵌套的异常处理块](。-异常应该由一个地方抛出,而不是随处可见。
👇 try catch
function doSomeThing(str) {
return JSON.parse(str)
}
function successFn(val) {
console.log('执行成功',val)
}
function doErrorThing(err) {
console.log('执行失败',err)
}
// 原try catch
function tryCatchFn() {
try{
doSomeThing('{}')
successFn()
}catch(err){
doErrorThing(err)
}
}
tryCatchFn()👇 TryFunctor/CatchFunctor
...
// 创建2个普通函子
const TryFunctor = (val) => ({
// try函子的next会组合并执行
next: fn => TryFunctor(fn(val)),
// run接收2个回调函数,只执行第一个
run: (errCallBack, successCallBack) => successCallBack(val)
})
const CatchFunctor = (val) => ({
// catch函子的next仅提供链式并不取next里的函数
next: () => CatchFunctor(val),
// run接收2个回调函数,只执行第二个
run: (errCallBack, successCallBack) => errCallBack(val)
})
// trycatch 函子
function TryCatchFunctor(fn) {
try{
return TryFunctor(fn())
}catch(err){
return CatchFunctor(err)
}
}
TryCatchFunctor( () => doSomeThing('{"name":"a"}') )
.next(res => res.name)
.run(doErrorThing, successFn)👆 可以看出trycatch函子,依然使用着trycatch,但是巧妙的结合函子的结构转化为了链式处理本来分离的代码块(try代码块、catch代码块)
只是用try执行一个函子、catch执行另一个函子,这两个功能函子,在普通函子的基础上
- 改造了catch函子的next函数仅支持链式调用不处理next里的参数
- 改造了2个函子的run函数,接收成功和失败2个回调函数,并分别执行对应的回调函数
使用上,会发现非常像promise
TryCatchFunctor( 要兜底的代码块 )
.next( 成功情况下的执行函数 )
.run( 失败情况下的执行函数, 成功并链式处理后的执行函数)但是!
既然我们理解了trycatch函子的本质还是trycatch,那用函数组合不是也能实现吗? 👇 函数组合形式处理trycatch
function tryCatchCompose(...fns) {
return (errCallback, successCall) => {
try{
const composeFn = compose(...fns)
const res = composeFn()
successCall(res)
} catch(err) {
errCallback(err)
}
}
}
const tryCatchDoSomething = tryCatchCompose(
res => res.name,
() => doSomeThing('')
)
tryCatchDoSomething(doErrorThing, successFn)最后再来比较一下
// 原try catch
function tryCatchFn() {
try{
const res = doSomeThing('')
const name = res.name
successFn(name)
}catch(err){
doErrorThing(err)
}
}
tryCatchFn()
// 函子形式
function tryCatchFn() {
return TryCatchFunctor( () => doSomeThing('') )
.next(res => res.name)
}
tryCatchFn.run(doErrorThing, successFn)
// 函数组合形式
const tryCatchFn = tryCatchCompose(
res => res.name,
() => doSomeThing('')
)
tryCatchFn(doErrorThing, successFn)这是比较 pure 的处理错误的方式
同理 ifelse函子,本质上还是用了ifelse,只是不放到外面使用罢了
// 接着用上面的trycatch例子,根据返回值是否为null做后续操作
const res = TryCatchFunctor( () => doSomeThing('{"name":"a"}') )
.next(res => res.name)
.run(doErrorThing, successFn)
// trycatch 函子
function IfNullFunctor(val) {
val != null ? TryFunctor(val) : catchFunctor(null)
}
// 非null时,执行链式的一些处理函数,null时进入null的回调
IfNullFunctor(res)
.next( res => console.log('非null时链式执行'))
.run(() => 'is null', () => 'not null' )👆 这里的ifelse依然用到了try函子和catch函子,作为if函子和else函子 因此try函子和catch函子,更常被叫做left函子和right函子,对应run时执行第一个回调函数和第二个回调函数
🤔思考: 但是ifelse的例子里,只允许if条件的链式操作。如果else里也需要拿到res来做链式操作怎么办?
链式的嵌套地狱弊端就会出现?(当然,可以通过包一层让嵌套不发生?)
🤔思考: 为什么要干掉ifelse
到目前为止,依然是除了链式处理写法组合顺序更直观之外,函子并没有拉开函数组合的优势 😤
IO函子
按需组合不同功能函子
纵观整个函数式编程的核心就在于把一个个的小函数组合成更高级的函数。 举个函数组合的例子:如果想给任何 Functor 应用一个统一的 map ,该如何处理?答案是 Partial Application:
const partial =
(fn, ...presetArgs) =>
(...laterArgs) =>
fn(...presetArgs, ...laterArgs);
const double = n => n * 2
const map = (fn, F) => F.map(fn)
const mapDouble = partial(map, double)
const res = mapDouble(Box(1)).fold(x => x)
console.log(res) // => 2👆 关键在于 mapDouble 函数返回的结果是一个等待接收第二个参数 F (Box(1)) 的函数; 一旦收到第二个参数,则会直接执行 F.map(fn) ,相当于 Box(1).map(double) ,该表达式返回的结果为 Box(2) ,所以后面可以继续 .fold等等链式操作。
🤔️ 这个例子哪里就证明了我们比函数组合更需要函子????
副作用具象起来,到底是指? 如果一个函数或者表达式除了返回一个值之外,还与外部可变状态进行了交互(读取或写入),则它是有副作用的。
const differentEveryTime = new Date()- IO就是一种副作用!
所谓的调用接口会带来副作用是指? 调用接口的输入是固定的,接口的输出则跟网络、后端逻辑、数据库等相关,并不是单纯根据输入在内部变量交互后得到相同的输出 副作用具像化,也就是这整个函数就是副作用,而不是说输出或是别的变量是副作用
纯函数 (Purity) 输出仅由输入决定,且不产生副作用(Side effects)。 如函数内部使用到了除了输入的变量,还用到了外部变量,则这个函数不纯
从写法上看函子是一个可以链式调用的类 如
[].map(fn1).map(fn2)、[].filter(fn1).filter(fn2)、new Promise(asyncFn).then(fn1).then(fn2)
🤔: 组合写法和链式写法,都是为了封装复用传递结果的这段逻辑。如何选择?
从作用上,据说函子可以把本来有的函数副作用,延迟到最后的时候出现,而在编写链式代码时不会有副作用 副作用使用函子进行统一管理
🤔 ??? 怎么就消除了副作用了?
说到底,函数组合、链式调用,原子化函数的过程就已经把副作用给消除了吧?
针对随着链式调用写法的一些问题如
- 中途参数结果为null导致js异常的处理
- 中途js异常的错误定位与抛出 (这些在函数组合时也存在吧)
针对函子已经封装了一层的函数调用,可以额外扩展的功能
- 惰性处理,增加一个运行函数run,整个链式调用的最后一步运行
.run()才开始从头执行- 柯里化就实现了惰性调用,设置好一些常量参数
- 链式处理异步
- 函子作为函子的操作函数时,由于函子是对象,需要
.value解出来,额外处理这种嵌套函子的场景
函子的实际场景 vue
- vue3的 function-api
- vue3各种computed watch onMounted导入再setup中自行组合
react
- components
- redux compose
ramdajs rxjs
如何编写高质量的 JS 函数(4) --函数式编程[实战篇]
没有提到函子知识,不代表我没有实践过,正是因为我实践过,才决定不提它,因为对于前端来说,有时候你要顾及整个团队的技术,组合和柯里还有高阶函数等还是可以很好的满足基本需求的。