http缓存
关于http缓存的背景以及意义,这里跳过不讲(主要由于http的无状态导致的性能损耗),直接从http缓存的流程和如何配置讲起 目前正在啃《图解http协议》之后会按照书本的每一章出文章,对于常见的http相关问题会单独讲(挖坑+1)
先记住几个概念
- 强缓存: 浏览器不发起http请求,直接从浏览器缓存中读取资源
- 协商缓存:浏览器发起http请求,服务端只返回状态码让浏览器读取缓存
- http1:最早期的http协议
- http1.1:优化缓存策略升级后的http协议
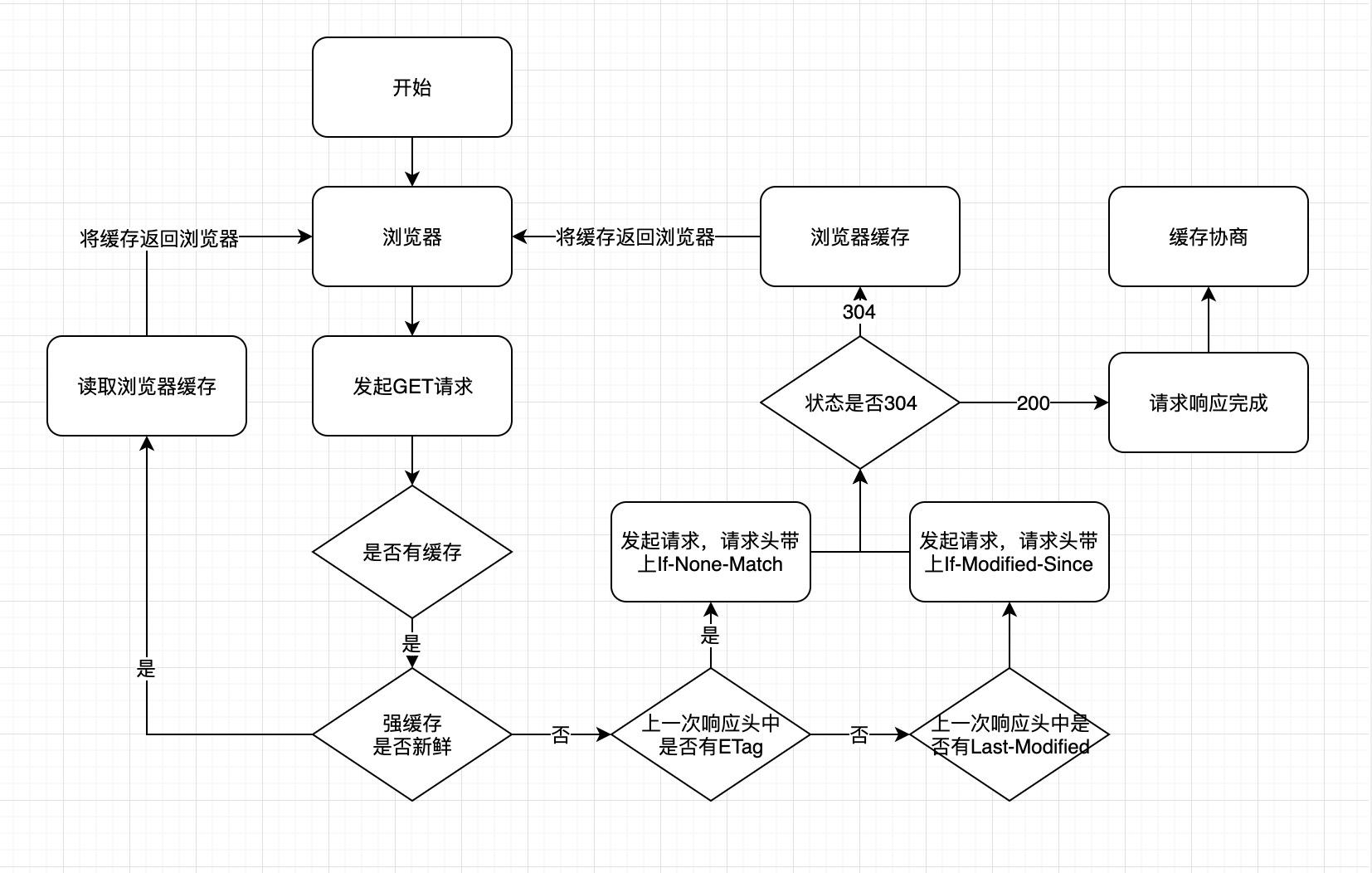
浏览器http缓存流程
这里忽略浏览器一个请求发起的所有过程(DNS解析、TCP、HTTP)
浏览器在客户端,会有一个内存空间用于存储有http缓存相关头的每次有响应的http请求
在下一次请求发出前,浏览器会到内存空间找到相同url的http请求 如果上一次http请求的响应头中有http缓存相关的字段 将判断是否命中强缓存,如果是则不发起请求,如果不是则把缓存相关的响应头字段处理成相应的请求头字段发出 即
- 我们可以把http强缓存过程当成是浏览器发起请求前发生的
- http协商缓存过程当成是服务端响应的时候发生的
以上仅是浅显的猜测,具体的流程未知
强缓存
如上的浏览器http缓存流程,http强缓存发生在浏览器发起请求前
强缓存分为 Disk Cache (存放在硬盘中)和 Memory Cache (存放在内存中),存放的位置是由浏览器控制的。
Expires
用于设置静态资源的过期时间。它的值一个GMT格式的时间字符串,比如expires:Fri, 27 Jul 2029 13:38:54 GMT。 这个时间代表着这个资源的失效时间,在此时间之前命中缓存。
缺点: 浏览器端时间和服务器时间不一致的时候,会有缓存有效期不准的问题(是双方各自的绝对时间)
Cache-Control
Cache-Control 是 HTTP/1.1 中新增的属性,在请求头和响应头中都可以使用 优先级在
Expires之上,即如果有Cache-Control,将无视ExpiresCache-Control MDN
常用的属性值如有:
- no-store:禁止使用缓存(包括协商缓存),每次都向服务器请求最新的资源
- no-cache:不使用强缓存,需要与服务器验证缓存是否新鲜
- max-age:单位是秒,缓存时间计算的方式是距离发起的时间的秒数,超过间隔的秒数缓存失效。与Expires相反,时间是相对于请求的时间。
- s-max-age:覆盖max-age或者Expires头,但是仅适用于共享缓存(比如各个代理),私有缓存会忽略它。
- private:专用于个人的缓存,中间代理、CDN 等不能缓存此响应(默认值)
- public:响应可以被中间代理、CDN 等缓存
- must-revalidate:在缓存过期前可以使用,过期后必须向服务器验证
Cache-Control的max-age是一个相对时间,例如3600,代表着资源的有效期是3600秒一个小时。由于是相对时间,并且都是与客户端时间比较,所以服务器与客户端时间偏差也不会导致问题。
流程大概可以是: 浏览器发起请求前,到内存中找到了上一次相同url相应的请求,并且上一次响应头中有max-age是3600秒,即一个小时,并且内存中的请求都会有个每次发起http请求都会生成的date,浏览器用当前时间和内存中的请求时间,相减得到的秒数判断是否取内存中的相应结果。
👆 所以,第三第四次以及之后的请求都是与第一次请求(缓存下来的http)的时间做比较的,并不是与上一次请求做比较
根据http标准,如果请求头不携带任何关于缓存的标记而响应头有缓存相关字段,则缓存时间等于当前时间和 Last-Modified时间的差值的10%,等同于cache-control=max-age=(date - Last-Modified)/ 10,通过fiddler抓包可看到英文原文:No explicit HTTP Cache Lifetime information was provided.Heuristic expiration policies suggest defaulting to: 10% of the delta between Last-Modified and Date.
👆 一般请求都会设置上的,这种属于很极端的情况吧(面试造火箭?)
协商缓存
在浏览器决定不取强缓存时,发起了请求,服务端将根据请求头中http缓存相应字段,做出对应的响应
时间 Last-Modified/If-Modified-Since
协商缓存需要服务端配合 浏览器第一次请求一个资源的时候,服务器返回的header中会加上
Last-Modify,Last-modify是一个时间标识该资源的最后修改时间,例如last-modified:Fri, 20 Dec 2019 03:34:57 GMT。
第一次响应时,服务端需要在响应头中返回协商缓存相关的字段,浏览器完成第一次请求响应,会缓存相关的协商缓存字段
流程大概可以是:
- 浏览器发起请求前,到内存中找到了上一次相同url相应的请求,决定不走强缓存。将找到内存中的响应头中协商缓存相关的字段
Last-Modify,拼接到这次发起的http请求头中If-Modified-Since,开始发起请求。 - 服务器接收到请求,检查请求头中的协商缓存相关字段,发现有
If-Modified-Since,拿url相应的资源修改时间做比较,发现修改时间是相同的则直接返回304响应码,让浏览器取缓存。否则响应真实资源,并且响应头会带上新的Last-Modify
缺点:
- 不同服务器资源的修改时间精度可能不同,存在相同时间资源内容变更的情况。导致服务器判断本次请求返回304(后果严重,用户访问的是错误内容)
- 资源内容没有实质变化,但是修改时间更新了,如加了回车或是空格,如服务器资源是全量删除全量更新的。导致服务器判断本次请求返回200真实请求 (实际让浏览器取缓存就可以,性能浪费)
Etag/If-None-Match
Etag/If-None-Match返回的是一个校验码(ETag: entity tag)。 Etag:服务器响应请求时,告诉浏览器当前资源在服务器的唯一标识(生成规则由服务器定义)。nginx中,etag会默认增加,如果需要关闭,需要在配置文件中设置:etag off;
与👆 时间 Last-Modified/If-Modified-Since 类似,这种协商缓存比对流程相同,并且是互斥的关系,etag的优先级更高(即有etag将无视Last-Modified)
流程大概可以是:
- 浏览器发起请求前,到内存中找到了上一次相同url相应的请求,决定不走强缓存。将找到内存中的响应头中协商缓存相关的字段
Etag,拼接到这次发起的http请求头中If-None-Match,开始发起请求。 - 服务器接收到请求,检查请求头中的协商缓存相关字段,发现有
If-None-Match,拿url相应的资源的唯一标识做比较,发现资源唯一标识是相同的则直接返回304响应码,让浏览器取缓存。否则响应真实资源,并且响应头会带上新的Etag
ETag 有强弱校验之分,如果 hash 码是以 "W/" 开头的一串字符串,说明此时协商缓存的校验是弱校验的,只有服务器上的文件差异(根据 ETag 计算方式来决定)达到能够触发 hash 值后缀变化的时候,才会真正地请求资源
强缓存和协商缓存的整体流程图
不走强缓存的几种方式
Pragma
Pragma 只有一个属性值,就是 no-cache 注意不是属于Cache-Control下的某种场景,而是和Cache-Control、Expires 同级别的控制参数,
效果和 Cache-Control 中的 no-cache 一致,不使用强缓存,但是会协商缓存,需要与服务器验证缓存是否新鲜,在 3 个头部属性中的优先级最高。
使用nodejs实操http缓存策略
构建http服务
const http = require('http')
const fs = require('fs')
const server = http.createServer((request,resp)=>{
// resp.writeHead(200, {
// "Content-type": "text/html" // 不返回 浏览器也可以猜测出类型,但是一般都返回
// });
const html = fs.readFileSync('./dist/index.html','utf8')
resp.end(html)
})
server.listen(9080)
console.log('Server runing at part: 9080')👆 用nodejs起一个服务 localhost:9080 访问这个地址,会读取本地文件中的 dist/index.html,返回回去
fs.readFileSync()是同步方法,并且不需要await,第二个参数文件类型必须写上utf8不可省略nodejs的http服务默认返回状态码200,本次示例可以不设置响应状态Content-type浏览器也可以根据内容猜测,但是会有猜测性能损耗,实际场景必须带上相应类型,本次示例不设置- 完整http服务还要做好各种常规异常处理,本次示例不设置
- 启服务器失败
- 逻辑异常500
- 资源不存在404
- ...
设置强缓存Expires
const http = require('http')
const fs = require('fs')
const server = http.createServer((request,resp)=>{
const time = new Date()
time.setTime(time.getTime() + (10*1000)) // 时间戳计算单位是毫秒
res.setHeader('Expires',time.toUTCString())
const html = fs.readFileSync('./dist/index.html','utf8')
resp.end(html)
})
server.listen(9080)
console.log('Server runing at part: 9080')👆 设置10秒后的到期时间
- 设置到期时间是UTC日期格式,因此使用
toUTCString()转化 toUTCString()是日期对象的方法,因此计算时间要用setTime()- 日期对象转时间戳计算的单位是毫秒
浏览器验证发现刷新虽然每次响应头都有Expires,但是每次请求头都会带上Cache-Control: max-age=0 我们上面讲到了cache-control优先级高于expires,所以每次请求都不会走强缓存
这个请求头的Cache-Control,是浏览器地址栏直接发起get请求默认带上的
解决办法
- 改写成ajax请求访问我们的http服务,而不用浏览器地址栏直接get请求
- 浏览器开着一个get请求,再新开一个标签页,提前打开控制台,输入地址再次直接发起get请求。并且新开的标签页也不能刷新测试,只能重复开新的标签页测试,这样可以让浏览器不带上
max-age=0
设置强缓存Cache-Control: max-age
const http = require('http')
const fs = require('fs')
const server = http.createServer((request,resp)=>{
res.setHeader('Cache-Control','max-age=10')
const html = fs.readFileSync('./dist/index.html','utf8')
resp.end(html)
})
server.listen(9080)
console.log('Server runing at part: 9080')👆 设置10秒后的相对时间到期 同样用新开标签的形式进行验证
设置协商缓存最后修改日期
const http = require('http')
const fs = require('fs')
const server = http.createServer((request,resp)=>{
const stats = fs.statSync('./dist/index.html')
const lastModified = stats.mtime.toUTCString()
// resp.setHeader('Cache-Control','max-age=5')
// 如果要找的资源修改时间等于请求头中的缓存修改时间,则返回304
const requestModified = request.headers['if-modified-since']
if(requestModified && requestModified === lastModified){
resp.statusCode = 304;
resp.end()
return
}
resp.setHeader('Last-Modified',lastModified) // 浏览器请求头会自动带上 if-modified-since
const html = fs.readFileSync('./dist/index.html','utf8')
resp.end(html)
})
server.listen(9080)
console.log('Server runing at part: 9080')协商缓存会发现 状态码设置不生效,但是资源size可以看出来是走了304的
在html上加外链css尝试,可以看到有304状态生效,但是等一会再刷新,状态变成了200 资源size还是可以走了304 很奇怪,只有状态设置不生效 到safire浏览器尝试,发现可以正常304,这里的原因不明,以后知道了再回来补吧。。。
不影响我们http缓存测试
设置协商缓存Etag
可以先用上面代码示例来验证modified的缺点,如上所述,文件内容没有修改,也会重新请求,删除然后新建也会重新请求,精度在1秒内会请求旧的资源
const http = require('http')
const fs = require('fs')
const crypto = require('crypto')
const server = http.createServer((request,resp)=>{
resp.setHeader('Cache-Control','max-age=0')
const buffer = fs.readFileSync('./dist/index.html');
const hash = crypto.createHash('md5');
hash.update(buffer, 'utf8');
const md5 = hash.digest('hex');
const requestEtage = request.headers['if-none-match']
if(requestEtage && requestEtage === md5) {
resp.statusCode = 304;
resp.end()
return
}
resp.setHeader('etag',md5) // 浏览器请求头会自动带上 if-modified-since
const html = fs.readFileSync('./dist/index.html','utf8')
resp.end(html)
})
server.listen(9080)
console.log('Server runing at part: 9080')为了保证 lastModified 不影响缓存,把通过 Last-Modified/If-Modified-Since 请求头删除 然后修改 html,增加一个空格后再删除一个空格,保持文件内容不变,但文件的修改时间改变,发起请求,由于生成 ETag 的方式是通过对文件内容进行 MD5 加密生成,所以虽然修改时间变化了,请求返回了 304 ,读取浏览器缓存。
采用的是对文件进行 MD5 加密来计算其 hash 值。
注:只是为了演示用,实际计算不是通过 MD5 加密的,Apache 默认通过 FileEtag 中 FileEtag INode Mtime Size 的配置自动生成 ETag,用户可以通过自定义的方式来修改文件生成 ETag 的方式。
关于资源hash解决的问题
对于img,css,js,fonts等非html资源,我们可以直接考虑max-age配置的时间可以尽可能久,类似于缓存规则案例中,cache-control: max-age=31535000配置365天的缓存 需要注意的是,这样配置并不代表这些资源就一定一年不变,其根本原因在于目前前端构建工具在静态资源中都会加入戳的概念(例如,webpack中的[hash],gulp中的gulp-rev) 每次修改均会改变文件名或增加query参数,本质上改变了请求的地址,也就不存在缓存更新的问题 每次都是一次新的强缓存
DNS缓存
浏览器请求域名
- 浏览器从自身的DNS缓存中去查找
- 浏览器从本地host文件查找
- 浏览器从操作系统里的DNS缓存中查找
- 浏览器请求本地域名服务器(例如电信)
- 浏览器请求DNS服务器递归查找
此时获得源服务器IP,以及源服务器根据域名配置的负载均衡服务器CDN策略服务器IP 本地域名服务器将不直接返回源服务器IP,而是去访问CDN服务器,负载均衡后返回的中间服务器(代理服务器IP/CDN服务器?)
因此浏览器拿到并访问的是中间服务器IP(在浏览器显示的是域名)
关于域名解析过程(由右往左) 
CDN缓存
上述的http缓存都是客户端自己的缓存,即只有当我访问过一次并缓存才能走缓存
而CDN则可以做到多个客户端,只要有一个人访问,CDN服务器就可以缓存下来,下次其他人再访问到CDN就直接给你CDN中的缓存
当然客户端访问CDN,还是一个http请求,只不过比直接访问源服务器要更快
缓存CDN缓存的建议观看 什么是CDN?CDN能为我们做什么?我们为什么要了解他?-bilibili
当浏览器向CDN节点请求数据时,CDN节点会判断缓存数据是否过期,若缓存数据并没有过期,则直接将缓存数据返回给客户端;否则,CDN节点就会向服务器发出回源请求,从服务器拉取最新数据,更新本地缓存,并将最新数据返回给客户端。
CDN服务商一般会提供基于文件后缀、目录多个维度来指定CDN缓存时间,为用户提供更精细化的缓存管理
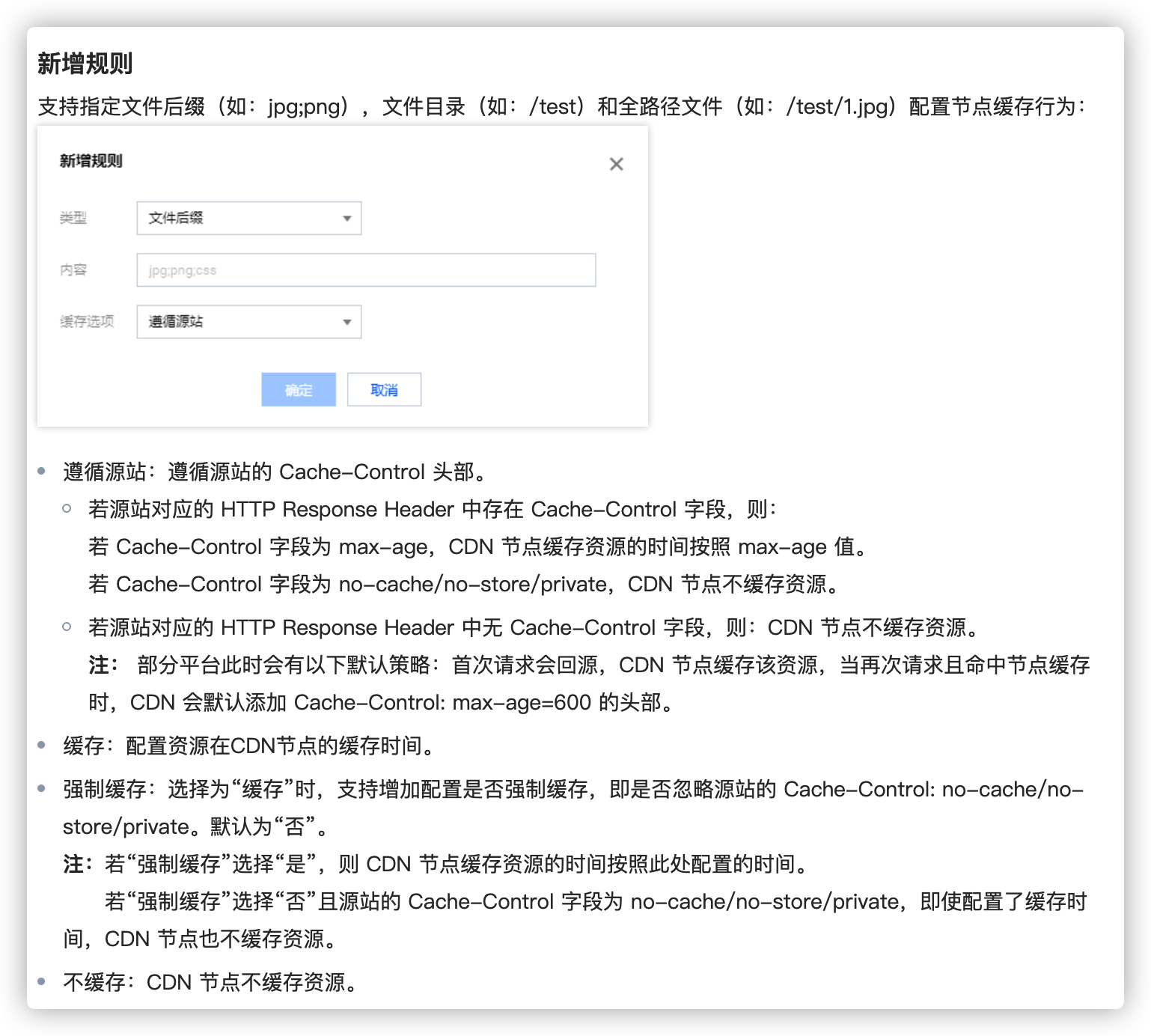 👆腾讯云CDN设置,不仅可以沿用源服务端设置的缓存策略,还可以自定义缓存策略
👆腾讯云CDN设置,不仅可以沿用源服务端设置的缓存策略,还可以自定义缓存策略
当CDN有自定义强缓存时间,并且源服务器更新了资源怎么办?
如果我们http缓存设置cache-control: max-age=600,即缓存10分钟,但cdn缓存配置中设置文件缓存时间为1小时,那么就会出现如下情况,文件被访问后第12分钟修改并上传到服务器,用户重新访问资源,响应码会是304,对比缓存未修改,资源依然是旧的,一个小时后再次访问才能更新为最新资源
当我们必须要在缓存期内修改文件,并且不想影响用户体验,那么我们可以使用cdn服务商提供的强制更新缓存功能,主要注意的是,这里的强制更新是更新服务端缓存,http缓存依然按照http头部规则进行自己的缓存处理,并不会受到影响。
CDN其他应用举例
除了静态内容,CDN服务器还可以获取动态内容,如服务器时间
因为客户端访问源服务器(中间链路长可能断连)时间可能不准或是获取不到,就可以让客户端获取CDN的服务器时间,源服务器也以CDN服务器时间为准
hash
在讨论理想缓存模型前,我们先看看资源hash的采用形式
在webpack等打包工具中,hash的生成规则分为: hash、contenhash... 我们只考虑最理想的contentHash
浏览器识别资源可以考虑缓存的标识是url,包括url参数
query-hash
那么我们可以利用参数做hash myapp/homePage.js?hash=1234 这样就能通过更新hash来使浏览器从重新发起全新请求(不走协商缓存,会是完全首次请求)
缺点
- hash的值需要我们自己拼上资源请求,如:html中的srcipt是带参数的、异步js的require带参数
- hash的值简单做法每次打包都是新的hash,会导致没更新的资源也重新请求。或者靠我们自己实现好的hash对应关系,只更新需要更新的hash
- 覆盖式部署,因为hash为参数,部署相同资源将是同名资源,上服务器会覆盖旧资源。如果资源要分类上传CDN服务器,会出现上传不同类资源更新先后顺序问题
优点
- 覆盖式部署,不会产生无用的旧资源
name-hash
把hash直接作为文件名 myapp/homePage.1234.js 减少我们自己实现hash和文件对应关系的工作量,我们只需要把contenthash输出到文件名,就可以做到精确的文件是否更新标识
优点
- 可以精确每个文件内容是否修改过的标识
- 如果资源分类上传CDN服务器,因为旧资源新资源会并存,所以先把被依赖被请求的资源上传,再上传入口资源就可以避免出现问题
缺点
- 随着时间推移,相同资源文件会留存很多份旧的,并且不好随便删除,需要制订好清除规则
解决问题
我们尝试不考虑复杂度,对上述两种方案做出合适的解决方案
query-hash hash和文件的对应关系
CDN+覆盖式部署
name-hash,清除旧资源机制
理想缓存策略
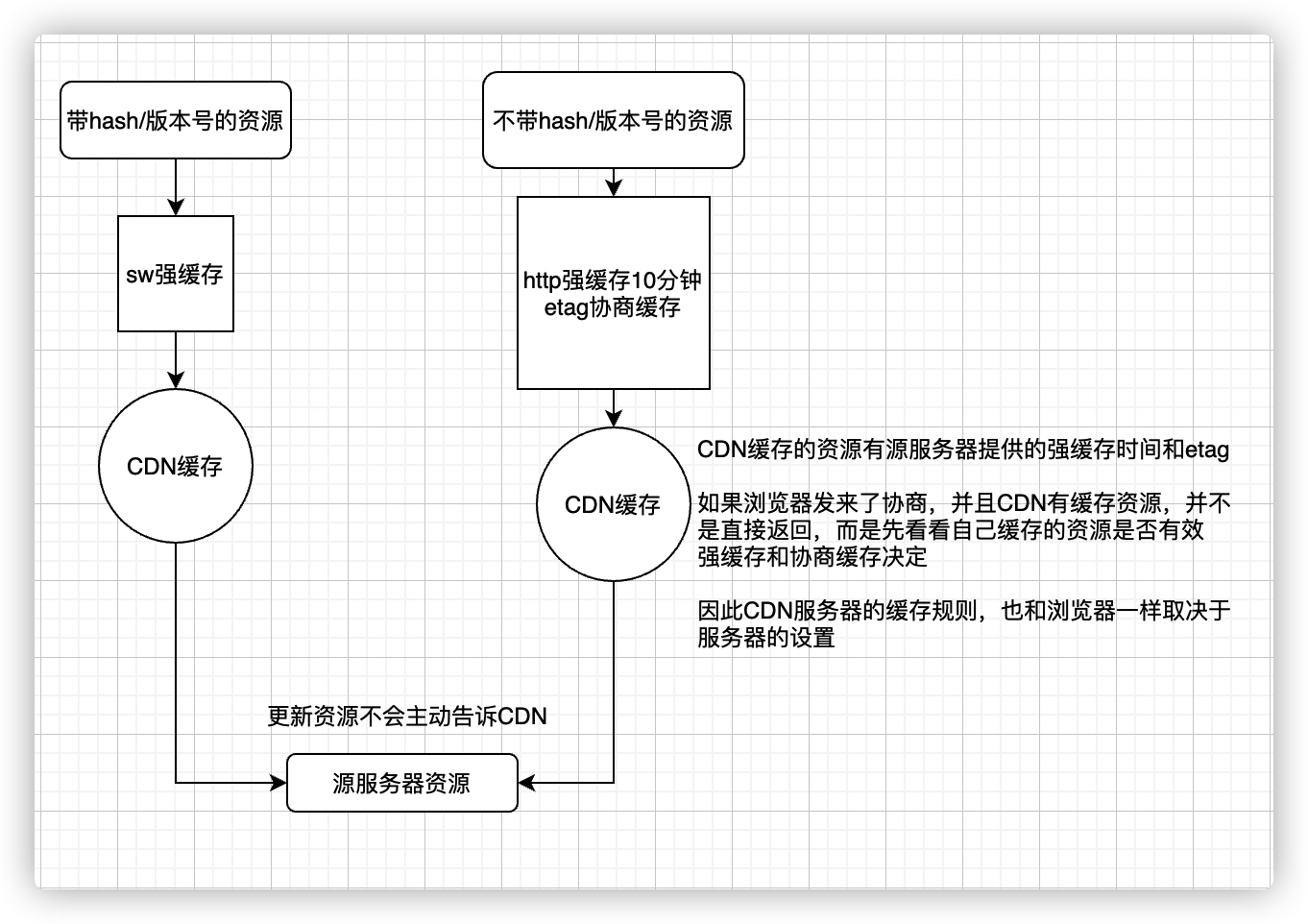
理想缓存策略,将资源简单的分为两种
- 带hash/版本号的资源(html、css、js、图片、字体等)
- 不带hash/版本号的资源(html、css、js、图片、字体等)
带hash的资源,相当于我们把浏览器是否要取缓存的判断交给了打包工具,更新了资源,浏览器就重新获取。 这里用service Worker,替代强缓存365天,只是为了资源可以离线获取,实际上用永久http强缓存相同效果
不带hash的资源,设置强缓存10分钟,协商缓存依靠etag。并且靠CDN缓存,CDN缓存在上面讲过,缓存机制和浏览器是类似
还有不缓存的如html资源,这里忽略
当然,这只是理想模型,实际场景要考虑很多因素
其他拓展
浏览器的gzip
- 给静态资源服务器http开启gzip,(nodejs来压缩?) 和缓存一样,只要有标识,浏览器就会自己去做解压
需要注意的是压缩的步骤由谁去做
webpack的hash、chunkhash和contenthash区别
hash:根据打包中所有的文件计算出的hash值。所有产物文件的filename获得的[hash]都是一样的。当修改任一文件,都会生成新的hashchunkhash:根据打包过程中当前chunk的文件计算出的hash值。如果Webpack配置是多入口配置,那么通常会生成多个chunk,每个chunk对应的出口filename获得的 [chunkhash] 是不一样的,1个chunk对应多个产物file,因此打包过程判断到其中一个file改变,将会生成新的chunkHash其他几个产物file 即使没有修改,也会使用新的hash 来不取缓存中资源contenthash根据产物文件内容计算出的hash值