IndexedDB
🤔 什么是 IndexedDB
IndexedDB 不属于关系型数据库(不支持 SQL 查询语句),更接近 NoSQL 数据库,可以简单认为是一个基于事务操作的 key-value 型前端数据库。它的 API 大部分都是异步。IndexedDB 语法比较底层,所以可以使用一些基于 IndexedDB 封装的库来简化操作:

浏览器里的indexedDB文件夹是存放什么数据的,为什么优酷会把网页端的流视频全缓存在这个文件夹中?
前端缓存现状
🤔 为什么用 IndexedDB
Web 应用程序的数据存储需求不断增长
对比 传统 Web 存储机制
| / | localStorage | sessionStorage | cookie | IndexedDB |
|---|---|---|---|---|
| 有效期 | 永久有效 | 关闭浏览器清除 | 非持久化,刷新页面则刷新 | 永久有效 |
| 存储容量 | 一般5MB | 一般5MB | 一般4KB | 无上限 |
| 存储类型限制 | 可JSON序列化的值 | 可JSON序列化的值 | 可JSON序列化的值 | 存储结构化克隆算法支持的任何对象 |
| 存取数据任务类型 | 同步 | 同步 | 同步 | 异步,同步 |
| 同域限制 | 是 | 是 | 是 | 是 |
- 数据存储: IndexedDB允许你在浏览器中存储大量的数据,包括 文本、二进制数据、JSON对象 等。这些数据以键值对的形式存储,使得数据的检索和管理非常方便。
- 事务支持: IndexedDB使用事务来确保数据的一致性和完整性。这意味着你可以以原子方式执行一系列操作,要么全部成功,要么全部失败,这有助于避免数据损坏和不一致。
- 索引: 你可以在IndexedDB中创建索引,以便更快速地查询数据。索引允许你根据非键属性来搜索数据,而不仅仅是键本身。
- 异步操作: IndexedDB是异步的API,这意味着你需要使用回调函数、Promise或async/await来处理数据库操作,以防止阻塞主线程。
- 存储限制: 不同浏览器对IndexedDB的存储容量有不同的限制,通常在几百MB到几GB之间。这取决于浏览器和用户的设置。
- 兼容性: 大多数现代浏览器都支持IndexedDB,包括Chrome、Firefox、Edge和Safari等。
对比 Service Workers
| / | IndexedDB | Service Workers |
|---|---|---|
| 数据结构 | 是一种客户端数据库,支持复杂的数据结构。它可以存储结构化数据,如键值对、对象和数组 | 通常用于缓存HTTP请求的响应数据,可以存储已下载的文件或资源 |
| 离线支持 | 专注于离线数据存储,使应用程序在离线时能够访问和操作数据 | 通过缓存HTTP响应来实现离线支持,对于需要加载离线资源的应用程序非常有用 |
| 数据容量 | 可以存储大量数据,适用于需要离线存储大型数据集的应用 | 通常用于缓存较小的资源,如CSS、JavaScript和图像文件,不适用于大型数据集 |
| 查询 | 支持高级查询,包括索引和范围查询,适用于复杂数据检索 | 不支持高级查询功能,只能存储和检索整个资源 |
| API复杂性 | IndexedDB的API相对较复杂,需要编写更多的代码来执行操作 | 相对于IndexedDB,Service Workers的缓存API较为简单,容易实现资源缓存 |
选择适当的存储技术取决于应用程序的需求:
如果应用需要复杂的数据操作、大容量数据存储、高级查询和数据模型,则IndexedDB是更好的选择。这适用于需要大规模数据存储和离线支持的应用,如任务管理器、文档编辑器等。
如果应用主要需要离线资源缓存、快速的资源加载和简单的缓存策略,则Service Workers的缓存是更适合的选择。这适用于需要在离线状态下继续访问资源的应用,如新闻阅读器、博客网站等。
使用场景
主要体现在:离线访问和大规模数据存储需求
A. 持久性存储的需求
- Web 应用需要一种可靠的方式来持久性地存储数据,以便用户在浏览器关闭或重新加载页面后能够保留数据。
配合单页面应用的 store
B. 大规模数据存储
- 一些 Web 应用需要存储大量数据,例如,在线文档编辑器需要保存文档的多个版本。
C. 离线访问
- 用户期望在没有互联网连接时也能使用 Web 应用。
D. 数据的结构化和索引
- 复杂的数据需要以结构化方式存储,并能够通过索引快速检索。
IndexedDB 不仅可以储存字符串,还可以储存二进制数据(ArrayBuffer 对象和 Blob 对象),所以我们可以把图片或者 3D 模型文件转化成 Blob 格式的文件,存在 IndexedDB 中,就可以解决免去二次加载时网络请求的时间。
IndexedDB 完全可以满足存储大体积文件的需求,并且 IndexedDB 可以 worker 中使用,包括 Web Worker 和 Service Worker
当 3D 需要进行复杂计算时,就可以利用 Service Worker 把一些数据存储在 IndexedDB 中或者通过 Web Worker 读取 IndexedDB 中的数据进行多线程计算。
不过需要注意的是 IndexedDB 也遵从同源协议(same-origin policy),所以只能访问同域中存储的数据,而不能访问其他域的。
底层 api 介绍
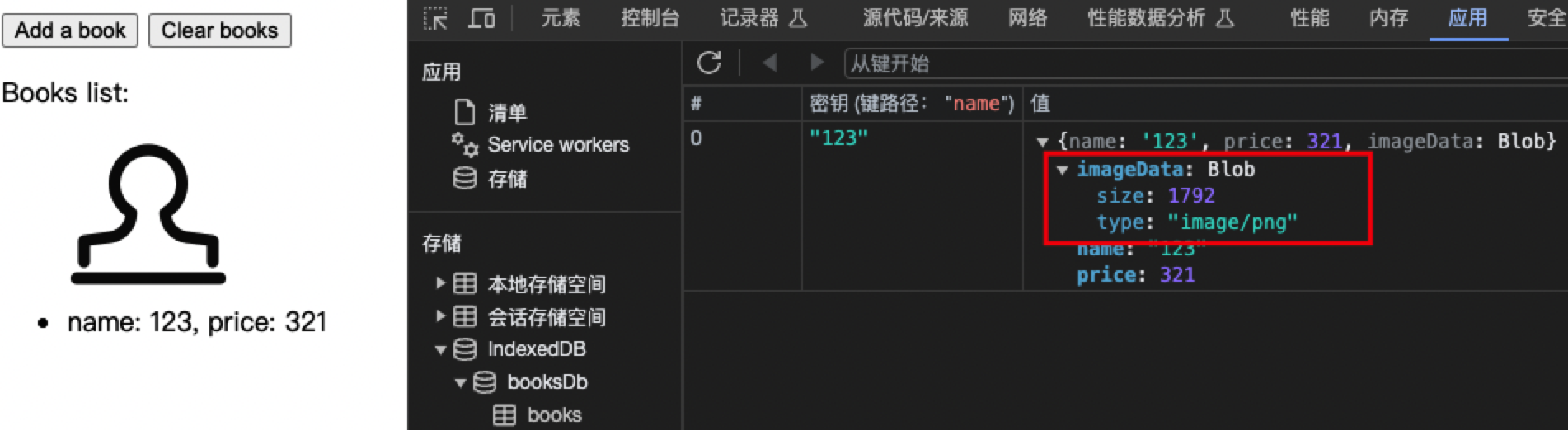
调试方法 打开f12可以在Application中看到IndexedDB中的数据库
- Database list(数据库列表):该列表显示了当前页面上存在的所有 IndexedDB 数据库。你可以选择其中一个数据库来查看其内容。
- Object store list(对象存储列表):显示选定数据库中的所有对象存储。你可以选择其中一个对象存储来查看它的数据和索引。
- Index list(索引列表):如果你选择了对象存储,此列表将显示选定对象存储中的所有索引。你可以选择其中一个索引来查看它的数据。
- 打开数据库(open 方法)
- 创建存储对象
- 添加、检索、更新和删除数据
- 使用事务
- 关闭数据库连接
// 打开数据库连接或创建新数据库
var request = indexedDB.open("myDatabase", 1);
// 处理数据库打开成功的情况
request.onsuccess = function(event) {
var db = event.target.result;
// 在数据库中创建一个存储对象
var objectStore = db.createObjectStore("customers", { keyPath: "id" });
// 添加数据
var customerData = { id: "001", name: "John Doe", email: "[email protected]" };
var addRequest = objectStore.add(customerData);
addRequest.onsuccess = function(event) {
console.log("Data added successfully");
};
// 关闭数据库连接
db.close();
};在了解上面的基础api后
👇 我们来做个 小示例DEMO (来自 mdn)
<!DOCTYPE html>
<script src="https://cdn.jsdelivr.net/npm/[email protected]/build/idb.min.js"></script>
<button onclick="addBook()">Add a book</button>
<button onclick="clearBooks()">Clear books</button>
<p>Books list:</p>
<ul id="listElem"></ul>
<script>
let db;
init();
async function init() {
// 1. 创建数据库booksDb或打开 版本为1
db = await idb.openDb("booksDb", 1, (db) => {
db.createObjectStore("books", { keyPath: "name" });
});
renderList();
}
async function renderList() {
let tx = db.transaction("books");
let bookStore = tx.objectStore("books");
let books = await bookStore.getAll();
if (books.length) {
listElem.innerHTML = books
.map((book) => `<li>name: ${book.name}, price: ${book.price}</li>`)
.join("");
} else {
listElem.innerHTML = "<li>No books yet. Please add books.</li>";
}
}
async function clearBooks() {
let tx = db.transaction("books", "readwrite");
await tx.objectStore("books").clear();
await renderList();
}
async function addBook() {
let name = prompt("Book name?");
let price = +prompt("Book price?");
let tx = db.transaction("books", "readwrite");
try {
await tx.objectStore("books").add({ name, price });
await renderList();
} catch (err) {
if (err.name == "ConstraintError") {
alert("Such book exists already");
await addBook();
} else {
throw err;
}
}
}
window.addEventListener("unhandledrejection", (event) => {
alert("Error: " + event.reason.message);
});
</script>
第三方库
1.localForage
localForage: 一个提供 name:value 的简单语法的客户端数据存储垫片(Polyfill),它基于 IndexedDB 实现,并在不持支 IndexedDB 的浏览器中自动回退只 WebSQL 和 localStorage。
- 背景: localForage 是一个使用了 IndexedDB、WebSQL 和 localStorage 等不同存储后端的库,它提供了一个统一的 API,使得在不同浏览器中存储数据变得更加容易。
- 解决的实际问题: localForage 解决了在不同浏览器中使用不同存储后端的复杂性,使开发者能够轻松地在多种存储引擎之间进行切换。
👀 看看 @zz-common/zz-utils/src/store.js
2.Dexie.js
- 背景: Dexie.js 是一个轻量级、Promise-based 的 IndexedDB 封装库,旨在简化 IndexedDB 的使用,尤其是在异步操作方面。
- 解决的实际问题: Dexie.js 使得 IndexedDB 更容易使用,提供了类似于数据库的 API,同时保留了 IndexedDB 的强大性能。
👀 看看 chrome-extension-lanhu/storage/imagedb.ts
3.IDB.js
- 背景: IDB.js 是一个小型的 IndexedDB 封装库,旨在提供一个更简化的 IndexedDB API,特别适用于小型项目和快速原型。
- 解决的实际问题: IDB.js 通过简化 IndexedDB API,减少了开发者的学习曲线,使得在小型项目中更容易使用 IndexedDB。
无论选择哪个库,IndexedDB 仍然是其底层存储引擎,因此理解 IndexedDB 的基本概念对于使用这些库仍然是有益的
这些库的目标是简化 IndexedDB 的使用,提供更高级的功能,并帮助开发者解决复杂的数据存储和同步问题。
实际应用
图片上传离线管理
上传失败阻塞问题
上传失败,可以离线住,重新上传,不需要打开蓝湖重新上传失败的图片
上传日志
存储功能
数据同步和离线支持:IndexDB 可以在离线状态下存储和检索数据,适用于需要支持离线操作或数据同步的应用场景。
适用场景:IndexDB 适用于需要在浏览器端存储大量结构化数据并进行高效检索的应用,例如任务管理应用、笔记应用、邮件应用等
数据同步和云存储整合
- 基于 IndexedDB 的离线应用
- 数据同步和云存储整合
场景描述:
- 假设我们正在开发一个在线图片编辑,用户可以在浏览器中创建、编辑和撤销。这个应用需要在离线时继续工作,以便用户可以在没有网络连接的情况下查看和编辑任务列表。
数据同步:
- 定时同步,触发数据同步过程。这个过程可以包括将本地更改上传到云端服务器以确保数据的最新版本,以及从云端服务器下载任何新的任务或更改。
WebAssembly 与 IndexedDB 的结合
- 利用 WebAssembly 提高性能
- 强调WebAssembly在数值计算和性能密集型任务方面的优势
Web应用程序越来越复杂,需要执行计算密集型任务,例如3D图形渲染、数据分析和模拟等。传统的JavaScript在这些任务中可能会面临性能瓶颈,因为它是一种解释性语言。
WebAssembly通过引入一种低级字节码,可以在浏览器中高效运行,充分利用硬件资源。这使得我们可以将性能密集型任务移至WebAssembly模块中,以显著提高应用程序的性能。
A. 为什么结合它们?
引出问题:如何在Web应用中充分利用WebAssembly的性能,同时利用IndexedDB提供的离线数据存储?
在WebAssembly模块中执行高性能任务,例如图形渲染或复杂计算。
利用IndexedDB在本地存储和离线情况下保存WebAssembly模块需要的数据。
提供更好的用户体验,用户可以在离线时仍然访问应用程序并执行任务,而不会受到性能限制。
实际应用场景
一个3D图形编辑器的Web应用程序。
WebAssembly用于高性能的3D图形计算,而IndexedDB用于离线存储和持久性保存用户的设计
WebAssembly的角色:
- 3D图形编辑器需要进行复杂的数学和图形计算,例如渲染、光照和纹理映射。
- 我们可以使用WebAssembly编写高性能的图形渲染引擎,并将其编译为WebAssembly模块。
- 当用户在编辑器中进行3D建模或渲染时,WebAssembly模块可以以接近本地代码的速度执行计算,提供流畅的用户体验。
IndexedDB的角色:
- 用户在编辑器中创建了复杂的3D模型,这些模型可能包括纹理、材质和场景数据。
- 这些数据需要在本地存储以供用户在不同会话中重新访问。
- 我们可以使用IndexedDB来存储这些3D模型的数据,包括二进制纹理图像和模型文件。
- 当用户重新打开应用程序时,WebAssembly模块可以从IndexedDB中检索所需的数据,从而无需重新下载或生成,提高了应用程序的加载速度。
为用户提供更出色的3D编辑体验。这种结合充分发挥了每个技术的优势,解决了Web应用程序面临的性能和数据存储挑战。
a. 应用程序离线访问: - 当用户离线时,Web应用程序可以继续运行,因为WebAssembly模块和IndexedDB中的数据都存储在本地。
b. WebAssembly模块的重新加载: - 在应用程序重新加载时,WebAssembly模块可以通过从IndexedDB中检索数据来重新初始化并继续运行,而不必重新下载或重新计算资源。
c. 数据的检索: - 使用IndexedDB事务来检索之前存储的3D模型数据和其他资源。这可以通过在IndexedDB存储对象上执行适当的查询操作来完成。
4. 数据同步和冲突解决:
a. 同步策略: - 当用户在离线时对数据进行更改时,必须制定一种同步策略,以确保与在线版本的数据同步。 - 常见的策略包括版本控制、增量更新或冲突解决算法。
b. 冲突解决: - 考虑到多用户和多设备的情况,必须解决潜在的数据冲突。这可以通过合并数据、使用时间戳或采用其他策略来解决。
总结
虽然 Web Storage 对于存储较少量的数据很有用,但对于存储更大量的结构化数据来说,这种方法不太有用。
IndexedDB 主要用于客户端存储大量结构化数据(包括, 文件/ blobs)。该 API 使用索引来实现对该数据的高性能搜索
允许我们存储和检索用键索引的对象;可以存储结构化克隆算法支持的任何对象
我们只需要指定数据库模式,打开与数据库的连接,然后检索和更新一系列事务。
注意缓存的清除、更新
- 有效期
- 缓存淘汰算法 LRU 是 Least Recently Used (更新顺序)