treeShaking
treeShaking 原理
很多文章以及打包工具介绍 tree-shaking 功能都是讲解它的现象、效果和必须基于 ESM
就仿佛只要用了 ESM 那么 tree-shaking 就是自动实现的
Rollup also statically analyzes the code you are importing, and will exclude anything that isn't actually used.
Since this approach can utilise explicit import and export statements, it is more effective than simply running an automated minifier to detect unused variables in the compiled output code.
👆
this approach指的是Rollup对编译前的代码做statically analyzes the code比传统的
Webpack用压缩器来扫描编译后的代码内容中未使用的变量 要更有效
我们需要明白 statically analyzes 是一个手动的步骤,而不是自动的
因为 静态分析 是对编译前的代码做扫描处理,因此模块化语法必须是静态的,而不是需要运行时才能清晰的语法,这也是 ESM 必须是现代打包器 tree-shaking 的大前提
这也是许多文章讲解 tree-shaking 时主要讲解的方向( ESM 和 CJS 的静态语法和运行时语法区别 )
这里聚焦在 静态分析逻辑,不会对前端模块化做过多讲解,可移步 前端模块化
手写 statically analyzes 静态分析
测试代码
👇 src/index.js
function add(a,b){return a+b}
function mul(a,b){return a*b}
const c=9;
const d=10;
add(c,d);👇 dist/index.shaked.js
function add(a,b){return a+b}
const c=9;
const d=10;
add(c,d);0. 步骤
import * as acorn from "acorn";
import { output, readEntrier } from "./readWriterFile.js"
import { shaking } from './shaking.js'
// 1. 读取入口文件内容字符串
const buffer = readEntrier()
// 2. 代码字符串 转化为 AST 数据
const { body } = acorn.parse(buffer, {ecmaVersion: 2020})
// 3. 步骤:扫描所有声明的变量 扫描所有使用的变量,按照使用的变量 取 对应声明的变量,最后拼接成一个 pure 代码字符串
const afterShakingCodeStr = shaking(body)
// 4. 把代码字符串写入出口文件
output(afterShakingCodeStr)👆 只能摇掉一个 js 文件内的未使用代码 dead-code
没有实现分析依赖,并摇掉未使用的模块
1. 读取入口文件内容字符串
nodejs 的 fs 读取入口文件 src/index.js 的代码内容
import fs from 'node:fs'
export function readEntrier() {
const buffer = fs.readFileSync('./src/index.js').toString()
return buffer
}2. 代码字符串 转化为 AST 数据
用 acorn 依赖库,把代码内容字符串转化为 AST数据
import * as acorn from "acorn";
const { body } = acorn.parse(buffer, {ecmaVersion: 2020})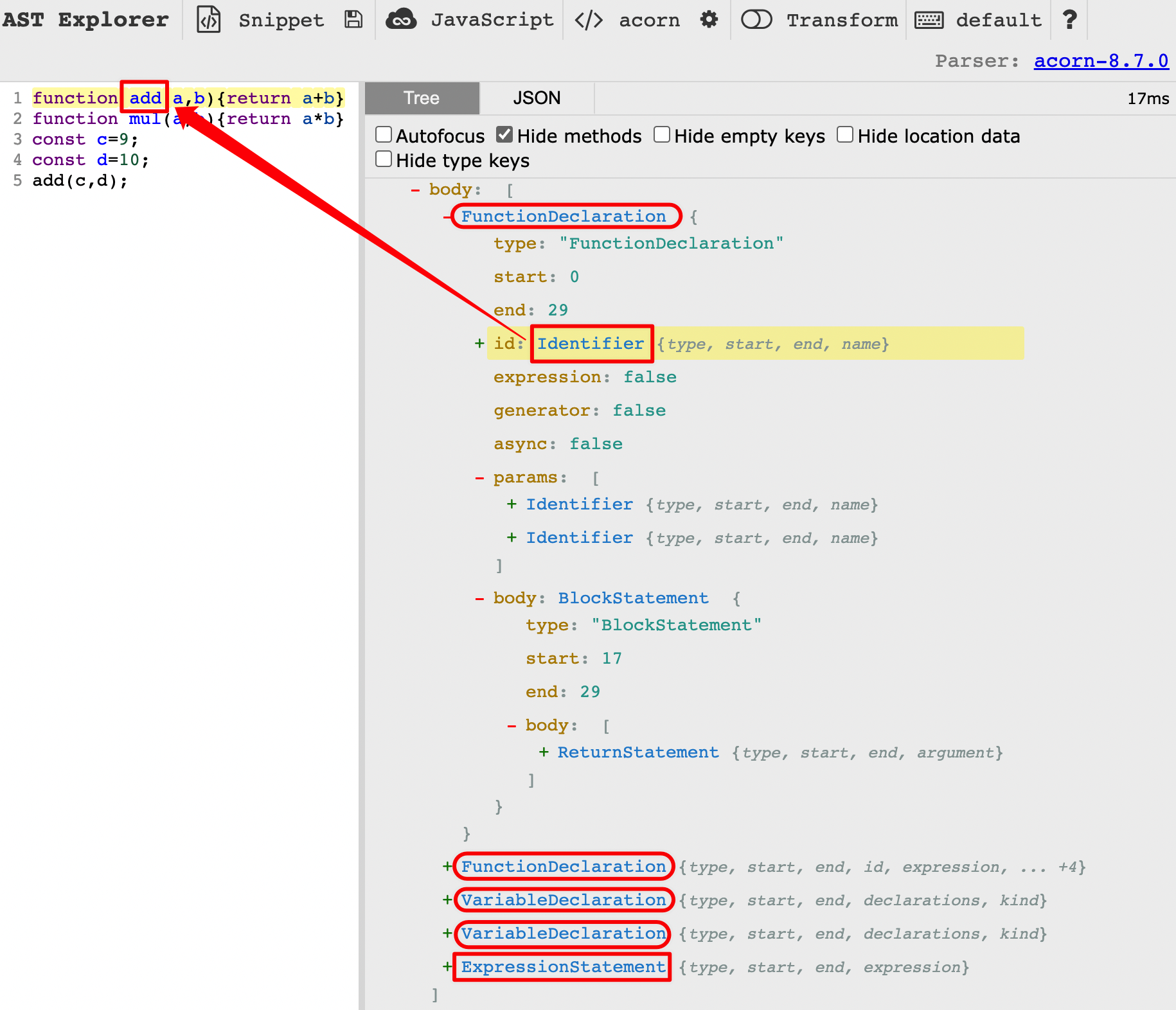
3. 根据 AST 找出有调用的代码并生成 pure 代码字符串
根据 AST 数据,找出
- 所有声明函数和变量
declarationList存储{ key:变量名 value:具体声明代码 } - 所使用调用过的变量名
calledDeclarationList存储[变量名, 变量名, ...] - 其它非声明的代码
code存储[代码语句, ...]
import {astToCodeString, visitNode, visitVariableDeclarator,visitIdentifier} from './astToCodeString.js'
export function shaking(astBody) {
// 所有声明函数和变量 `declarationList` 存储 `{ key:变量名 value:具体声明代码 }`
// 所使用调用过的变量名 `calledDeclarationList` 存储 `[变量名, 变量名, ...]`
// 其它非声明的代码 `code` 存储 `[代码语句, ...]`
let declarationList = new Map()
let calledDeclarationList = []
let code = []
astBody.forEach(function (node) {
// 函数声明 存放到 declarationList 的 Map 中
if (node.type == "FunctionDeclaration") {
const code = astToCodeString([node])
declarationList.set(visitNode(node.id), code)
return;
}
// 变量声明表达式,kind 属性表示是什么类型的声明,值可能是var/const/let
// declarations 数组 表示声明的多个描述,因为我们可以这样:let a = 1, b = 2
// 存放到 declarationList 的 Map 中
if (node.type == "VariableDeclaration") {
const kind = node.kind
for (const decl of node.declarations) {
declarationList.set(visitNode(decl.id), visitVariableDeclarator(decl, kind))
}
return
}
if (node.type == "ExpressionStatement") {
// 函数调用表达式,比如:setTimeout(()=>{})
// callee 属性是一个表达式节点,表示函数
// arguments 是一个数组,元素是表达式节点,表示函数参数列表
if (node.expression.type == "CallExpression") {
const callNode = node.expression
calledDeclarationList.push(visitIdentifier(callNode.callee))
const args = callNode.arguments
for (const arg of args) {
if (arg.type == "Identifier") {
calledDeclarationList.push(visitNode(arg))
}
}
}
}
// Identifier- 标识符,就是我们写 JS 时自定义的名称,如变量名,函数名,属性名,都归为标识符
// 表示的是使用变量? 存放到 calledDeclarationList 数组中
if (node.type == "Identifier") {
calledDeclarationList.push(node.name)
}
code.push(astToCodeString([node]))
});
}👆 至此一个入口文件的变量是否被调用过(有效代码)的关系已经清晰了
遍历调用的变量名数组 去所有声明函数和变量 declarationList 中根据变量名key,取出对应的代码value
const afterShakingCodeList = [
...(calledDeclarationList.map( c => declarationList.get(c) )),
...code,
]
const afterShakingCodeList = afterShakingCodeList.join('')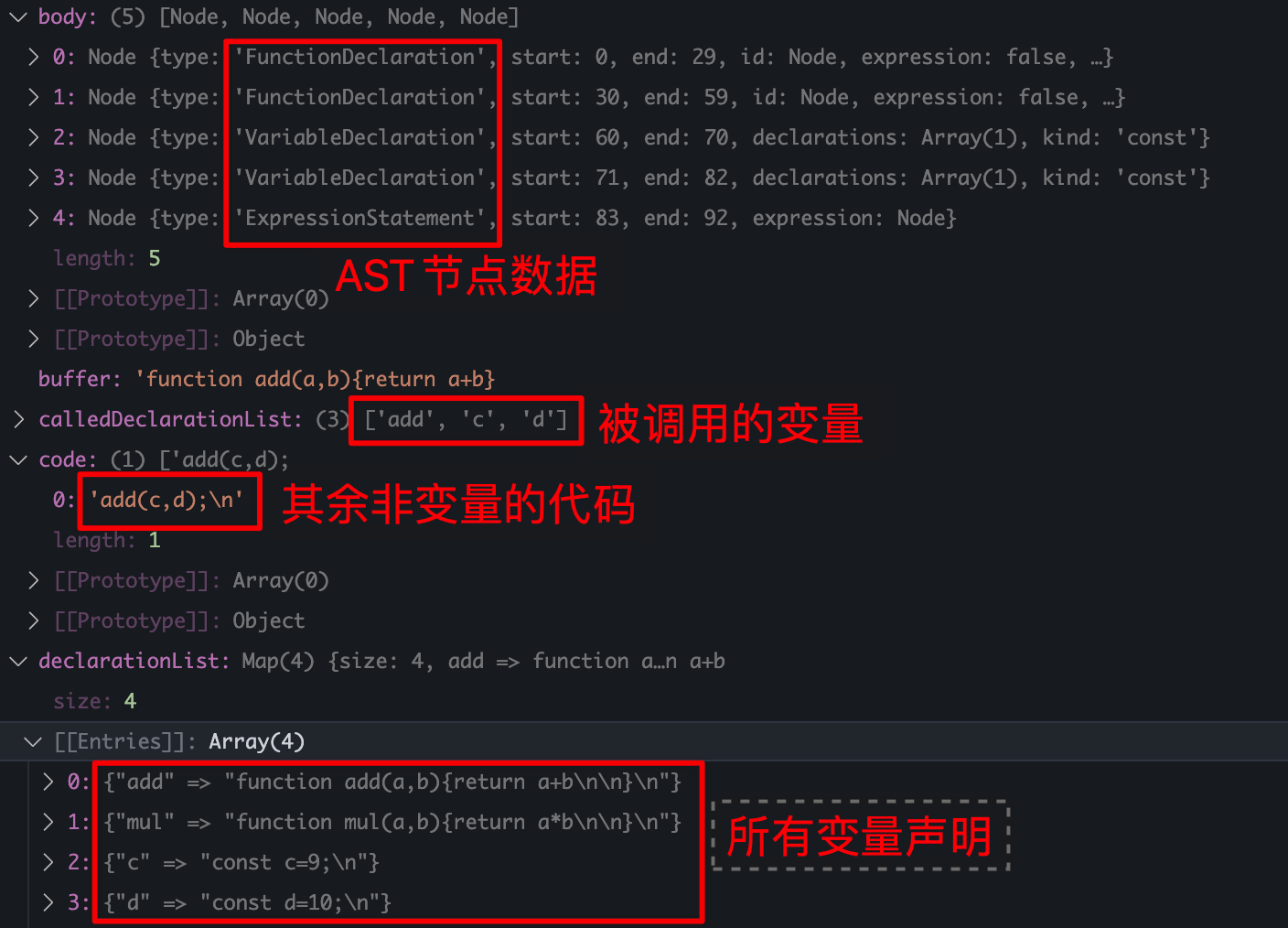
4. 把代码字符串写入出口文件
最后把这些代码数组拼接到字符串,写进一个结果文件
export function output(code) {
fs.writeFileSync('dist/index.shaked.js', code)
}总结
可以看出 静态分析 statically analyzes
- 重点在找出会被调用的有效代码,基于
AST数据 - 难点在于这个扫描的算法
- 而👆 这个步骤极度依赖代码的静态性,如果被调用这件事是不可确定的,那么
tree-shaking也将无从下手